Die aktuellen Entwicklungen zeigen unsere (europäische) digitale Abhängigkeit von amerikanischen Tech-Riesen. Ob es sich um Starlink, ein Unternehmen von Elon Musk, oder um OpenAI (dominiert von Microsoft), Amazon Cloud, Google usw. handelt, überall haben sich die amerikanischen Tech-Unternehmen in Europa durchgesetzt.
Immer mehr Privatpersonen, Unternehmen und Verwaltungen überlegen allerdings aktuell, ob es nicht besser ist, europäische Alternativen zu nutzen, um die genannte digitale Abhängigkeit zu reduzieren.
Die Website European alternatives for digital products hat nun angefangen, verschiedene europäische Alternativen zu den etablierten Angeboten aufzuzeigen. Die Übersicht ist nach verschiedenen Kategorien gegliedert. Die Website ist eine Initiative eines österreichischen Softwareentwicklers und steht erst am Anfang.
Insgesamt kann diese Website in die Initiative Sovereign Workplace eingeordnet werden, an dem wir uns auch schon länger orientieren. Dabei werden Vorschläge gemacht, welche Anwendungen auf Open Source Basis geeignet erscheinen.
Wir sind uns alle einig, dass Daten eine bedeutende Ressource für einzelne Personen, Unternehmen, Organisationen und ganze Gesellschaften darstellen. Einerseits müssen Daten offen verfügbar sein, andererseits allerdings auch geschützt werden. Insofern macht es Sinn, verschiedene Kategorien für Daten zu unterscheiden:
“Open data: data that is freely accessible, usable and shareable without restrictions, typically under an open license or in the Public Domain36 (for example, OpenStreetMap data); Public data: data that is accessible to anyone without authentication or special permissions (for example, Common Crawl data). Note that this data can degrade as web content becomes unavailable; Obtainable data: data that can be obtained or acquired through specific actions, such as licensing deals, subscriptions or permissions (for example, ImageNet data); Unshareable non-public data: data that is confidential or protected by privacy laws, agreements or proprietary rights and cannot be legally shared or publicly distributed” (Tarkowski, A. (2025): Data Governance in Open Source AI. Enabling Responsible and Systemic Access. In Partnership with the Open Source Initiative).
Es zeigt sich, dass es viele frei verfügbare Daten gibt, doch auch Daten, die geschützt werden sollten.
Die amerikanischen Tech-Konzerne möchten alle Daten für ihre Trainingsdatenbanken (LLM: Large Language Models) kostenlos nutzen können. Das Ziel ist hier, die maximale wirtschaftliche Nutzung im Sinne einiger weniger Großkonzerne. Dabei sind die Trainingsdaten der bekannten KI-Modelle wie ChatGPT etc. nicht bekannt/transparent. Die Strategie von Big-Tech scheint also zu sein,: Alle Daten “abgreifen” und seine eigenen Daten und Algorithmen zurückhalten. Ein interessantes Geschäftsmodell, dass sehr einseitig zu sein scheint.
Bei der chinesische Perspektive auf Daten liegt der Schwerpunkt darauf, mit Hilfe aller Daten politische Ziele der Einheitspartei zu erfüllen. Daran müssen sich alle Bürger und die Unternehmen – auch die KI-Unternehmen – halten.
In Europa versuchen wir einen hybriden Ansatz zu verfolgen. Einerseits möchten wir in Europa Daten frei zugänglich machen, um Innovationen zu fördern. Andererseits wollen wir allerdings auch, dass bestimmte Daten von Personen, Unternehmen, Organisationen und Öffentlichen Verwaltungen geschützt werden.
An dieser Stelle versucht die aktuelle amerikanische Regierung, Druck auf Europa auszuüben, damit Big-Tech problemlos an alle europäischen Daten kommen kann. Ob das noch eine amerikanische Regierung ist, oder nicht schon eine kommerziell ausgerichtete Administration wird sich noch zeigen. Das letzte Wort werden wohl die Gerichte in den USA haben.
Ich hoffe, dass wir in Europa unseren eigenen Weg finden, um offene Daten in großem Umfang verfügbar zu machen, und um gleichzeitig den Schutz sensibler Daten zu gewährleisten.
Es wundert daher nicht, dass sich die neue Regierung in den USA darüber beschwert, dass Europa die Entwicklung und Nutzung Künstlicher Intelligenz in Schranken regulieren will. Ich hoffe, Europa ist selbstbewusst genug, sich diesem rein marktwirtschaftlich ausgerichteten Vorgehen der USA zu widersetzen, ohne die Möglichkeiten einer Nutzung und Entwicklung von Künstlicher Intelligenz zu stark einzuschränken. Der Einsatz Künstlicher Intelligenz wird gravierende gesellschaftliche Veränderungen nach sich ziehen, sodass es auch erforderlich, gesellschaftlich auf diese Entwicklung zu antworten.
Neben China und den USA kann es Europa durchaus gelingen, beide Schwerpunkte (USA: Kapital getrieben, China: Politik getrieben) zur Nutzung von Künstliche Intelligenz in einem Hybriden Europäischen KI-Ansatz zu verbinden. Das wäre gesellschaftlich eine Innovation, die durchaus für andere Länder weltweit interessant sein könnte.
Open Euro LLM ist beispielsweise so eine Initiative, die durchaus vielversprechend ist. Wie in dem Screenshot zur Website zu erkennen ist, setzt man bei Open Euro LLM auf Offenheit und Transparenz, und auch auf europäische Sprachen in den Trainingsdatenbanken der Large Language Models (LLM). Beispielhaft soll hier der Hinweis auf Truly Open noch einmal herausgestellt werden:
Truly Open including data, documentation, training and testing code, and evaluation metrics; including community involvement
In Zukunft wird es meines Erachtens sehr viele kleine, spezialisierte Trainingsdatenbanken (SLM: Small Language Models) geben, die kontextbezogen in AI-Agenten genutzt werden können. Wenn es um Kontext geht, muss auch die kulturelle Vielfalt Europas mit abgebildet werden. Dabei bieten sich europäische Trainingsdatenbanken an. Siehe dazu auch
Seit Jahren und Jahrzehnten begeben wir uns in Deutschland in eine digitale Abhängigkeit, die für viele Menschen, Organisationen und die ganze Gesellschaft nicht gut ist.
Einzelne Personen merken immer mehr, wie digital abhängig sie von Facebook, X (ehemals Twitter), Instagram, WhatsApp, Twitch, TikTok usw. usw. sind. Ähnlich sieht es auch bei Unternehmen aus:
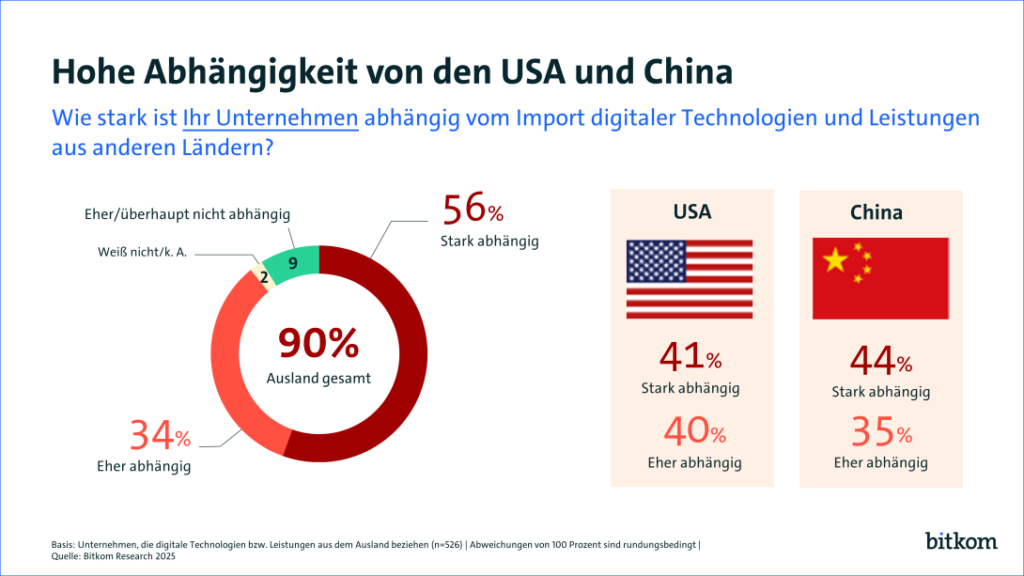
“90 Prozent der Unternehmen sind vom Import digitaler Technologien und Services aus anderen Ländern abhängig, insbesondere aus den USA und China” (Bitkom 2025).
Auch unsere Verwaltungsstrukturen haben sich an diese digitale Abhängigkeit begeben.
Durch diese Entwicklungen fällt es allen schwer, von dieser digitalen Abhängigkeit loszukommen. Ein Verhalten, das Abhängige grundsätzlich haben. Wie wir aus der Theorie der Pfadabhängigkeit wissen, kommt es im Aneignungsprozess z.B. digitaler Anwendungen zu einer Art Lock-in. Es fällt dann allen Beteiligten schwer, aus dem gewohnten Umfeld wieder herauszukommen.
Kann man nichts machen, oder? Doch! Auf europäischer Ebene gibt es seit längerem die Erkenntnis, dass wir in Europa wieder zu einer Digitalen Souveränität kommen müssen.
In dem Blogbeitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich gemacht, dass Europa, die USA und China unterschiedliche Ansätze bei dem Thema Digitale Souveränität haben. Diese grundsätzlichen Unterschiede zeigen sich auch in den vielen Large Language Models (Trainingsdatenbanken), die für KI-Anwendungen benötigt werden.
Es wundert daher nicht, dass in dem Paper Buyl et al. (2024): Large Language Models Reflect The Ideology of their Creators folgende Punkte hervorgehoben werden:
“The ideology of an LLM varies with the prompting language.”
In dem Paper geht es um die beiden Sprachen Englisch und Chinesisch für Prompts, bei denen sich bei den Ergebnissen Unterschiede gezeigt haben.
“An LLM’s ideology aligns with the region where it was created.”
Die Region spielt für die LLMs eine wichtige Rolle. China und die USA dominieren hier den Markt.
“Ideologies also vary between western LLMs.”
Doch auch bei den “westlichen LLMs” zeigen sich Unterschiede, die natürlich jeweils Einfluss auf die Ergebnisse haben, und somit auch manipulativ sein können.
Die Studie zeigt wieder einmal, dass es für einzelne Personen, Gruppen, Organisationen oder auch Gesellschaften in Europa wichtig ist, LLMs zu nutzen, die die europäischen Sprachen unterstützen, und deren Trainingsdaten frei zur Verfügung stehen. Das gibt es nicht? Doch das gibt es – siehe dazu
Immer mehr Privatpersonen und Organisationen realisieren, dass die populären Trainingsdaten (LLM: Large Language Models) für ChatGPT von OpanAI, oder auch Gemini von Google usw., so ihre Tücken haben können, wenn es beispielsweise im andere oder um die eigenen Urheberrechte geht. In diesem Punkt unterscheiden wir uns in Europa durchaus von den US-amerikanischen und chinesischen Ansätzen. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich. Darüber hinaus liegen die Daten der bekannten (closed source) LLMs zu einem überwiegenden Teil in englischer oder chinesischer Sprache vor.
“Multilingual, open source models for Europe – instruction-tuned and trained in all 24 EU languages…. Training on >50% non English Data. (…) This led to the creation of a custom multilingual tokenizer” (ebd.).
Neben der freien Verfügbarkeit (Open Source AI) (via Hugging Face) ist somit ein großer Pluspunkt, dass eine große Menge an Daten, nicht englischsprachig sind. Das unterscheidet dieses Large Language Model (LLM) sehr deutlich von den vielen englisch oder chinesisch dominierten (Closed Source) Large Language Models.
Insgesamt halte ich das alles für eine tolle Entwicklung, die ich in der Geschwindigkeit nicht erwartet hatte!
Fratini, S., Hine, E., Novelli, C. et al. Digital Sovereignty: A Descriptive Analysis and a Critical Evaluation of Existing Models. DISO3, 59 (2024). https://doi.org/10.1007/s44206-024-00146-7
Digitale Souveränität ist ein Begriff, der in den verschiedenen Regionen der Welt durchaus unterschiedlich interpretiert wird. In Deutschland hat beispielsweise das Bundesministerium des Innern den Begriff in einer Veröffentlichung zum Thema wie folgt beschrieben:
„Digitale Souveränität beschreibt die Fähigkeiten und Möglichkeiten von Individuen und Institutionen, ihre Rolle(n) in der digitalen Welt selbstständig, selbstbestimmt und sicher ausüben zu können“ (Bundesministerium des Inneren (2020): Digitale Souveränität).
In der Europäischen Union gibt es Initiativen, die den Sovereign Workplace mit Open Source Anwendungen propagieren, da die kommerziellen, marktgetriebenen Anwendungen (bis hin zur Künstlichen Intelligenz) durchaus kritisch gesehen werden. Der Grund dafür liegt u.a. auf der Argumentation, dass gute Trainingsdaten für Künstliche Intelligenz nur zu bekommen sind, wenn die Urheberrechte “nicht so genau” genommen werden. Common Corpus zeigt allerdings genau das Gegenteil.
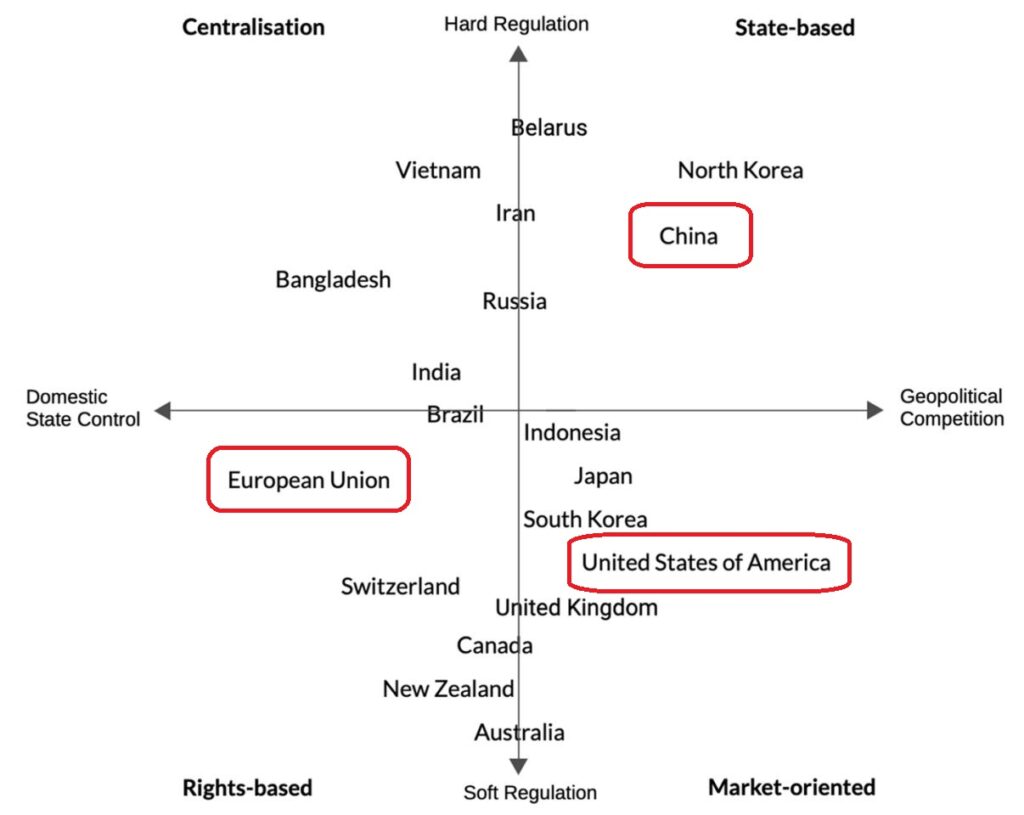
In einem Paper haben nun Fratini et al. (2024) die verschiedenen Perspektiven auf die Digitale Souveränität von verschiedenen Ländern in einer Grafik positioniert, in der es die Pole Hard Regulation >< Soft Regulation bzw. Domestic State Control >< Geopolitical Competition gibt (siehe Abbildung). Wie zu erkennen ist, liegen die USA im marktorientierten Bereich und China eher im staats-dominierten Sektor.
Die Europäische Union favorisiert eher einen rechte-basierten Ansatz und versucht, dem mit verschiedenen Grundsatz-Veröffentlichungen, wie dem EU Artificial Intelligence Act, gerecht zu werden. Die Autoren weisen berechtigt darauf hin, dass es eine einheitliche europäische Positionierung zur Digitalen Souveränität bisher nicht gibt, da die nationalen Regelungen noch kein einheitliches Bild ergeben. Dennoch ist durchaus ein Trend zu erkennen.
Meines Erachtens ist der von der Europäischen Union eingeschlagene Weg richtig. Es zeigt sich gerade in der Nutzung von mehr Open Source Anwendungen, dass es eine lebenswertere Alternative zu den amerikanischen oder chinesischen Vorgehen gibt – gerade im Sinne einer menschenzentrierten Society 5.0.
Wir in Deutschland, und auch in der Europäischen Union, rühmen uns für unsere Innovationsfähigkeit, doch hat dieses Bild in der letzten Zeit deutliche Risse bekommen. Wenn wir uns mit uns selbst (Vergleich der letzten Jahre), oder mit anderen Nationen in Europa vergleichen, sieht es mit der Innovationsfähigkeit ja noch recht gut aus.
Im Vergleich zu den USA oder China sind wir in Deutschland allerdings eher mittelmäßig, was die Innovationen betrifft, die zukünftig Potenzial für nachhaltiges Wachstum versprechen. In diesem Zusammenhang habe ich folgendes gefunden:
“Es birgt inhärente Risiken, Forschungs- und Entwicklungsanstrengungen auf inkrementelle Verbesserungen reifer Technologien wie in der Automobilindustrie zu fokussieren, da diese (nur noch) begrenztes Potenzial für nachhaltiges Wachstum bieten. (…) Wenn man der Überlegung folgt, dass die persistente Konzentration der EU-Unternehmen auf etablierte Technologie problematisch ist, kann man davon sprechen, dass Europa in einer Art »Midtech«-Falle steckt. Patentanmeldungen weisen auf den selben Trend hin” (ifo Schnelldienst 4 / 2024 | PDF).
Wie ich in unserem Blog schon an vielen Stellen erwähnt habe, ist die deutsche/europäische Sicht auf Innovation oft sehr selektiv. Wenn wir deutsche Innovationen mit vergleichbaren Werten aus der Vergangenheit vergleichen, gibt es auf der Ebene der Politik und auch auf der Ebene der Unternehmen nur Positives zu vermelden – was auch gemacht wird. Es vergeht kein Tag, in dem nicht darauf hingewiesen wird, wie innovativ Deutschland sei. Es ist eben alles relativ: Honi soit qui mal y pense.
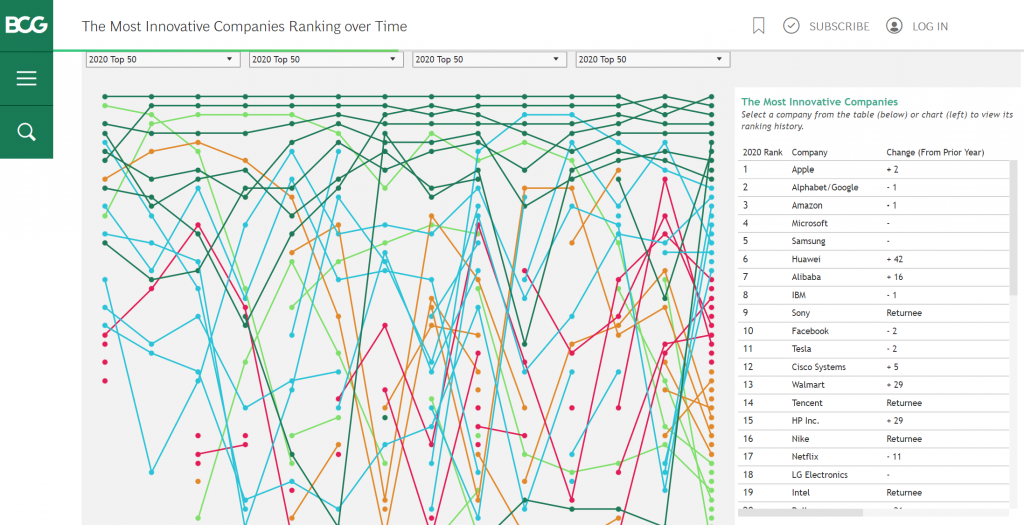
Vergleichen wir das deutsche Innovationssystem international, sieht es allerdings anders aus. Das weltweite Ranking der Boston Consulting Group zeigt seit 2005 eine deutliche Entwicklung. Die innovativsten Unternehmen kommen – bei einer Ausnahme (Samsung, Südkorea) – aus den USA oder China – und Europa/Deutschland schaut staunend zu. Als exportabhängige Nation sind wir von der Zukunftsfähigkeit von Produkten und Dienstleistungen, aber auch von der Zukunftsfähigkeit der politischen und rechtlichen Strukturen abhängig. Diese Zukunftsfähigkeit scheint in den letzten Jahrzehnten verspielt worden zu sein.
Wo sind deutsche/europäische Unternehmen wie Apple, Alphabet/Google, Amazon, Microsoft, Samsung, Huawei, Alibaba, IBM, Sony, Facebook (Top 10)?
In dem Beitrag The Lean Hardware Startup: From Prototype To Production (Techchrunch, 16.11.2013) wird deutlich, dass hochwertige Software aus dem Silicon Valley (USA) kommt und hochwertige Hardware immer stärker aus Shenzen (China). Shenzen ist somit nicht mehr nur die verlängerte Werkbank westlicher Konzerne, sondern immer mehr eine High-Tech Region, die die neuen Produktionsmöglichkeiten nutzt. Es stellt sich mir die Frage, welche Rolle Europa/Deutschland hier spielt, bzw. in Zukunft spielen wird.
Translate »
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK