In der Vergangenheit wurden hauptsächlich die Nachteile des klassischen, plangetriebenen Projektmanagements herausgestellt. Als Paradebeispiel (Negativ-Beispiel) wurde oft das Wasserfallmodell herangezogen, das nach der Meinung vieler sogenannter Experten nicht mehr zeitgemäß sei. Siehe dazu auch OpenProject: Anmerkungen zum Kritischen Weg und zu Meilensteinen und Einige Anmerkungen zum “Wasserfall-Modell” auf Basis des Originalartikels von Royce (1970.
Alles sollte (musste?) in Zukunft agil durchgeführt werden. Prominente Vorgehensmodelle waren und sind hier Scrum (Framework), Kanban, DevOps etc.
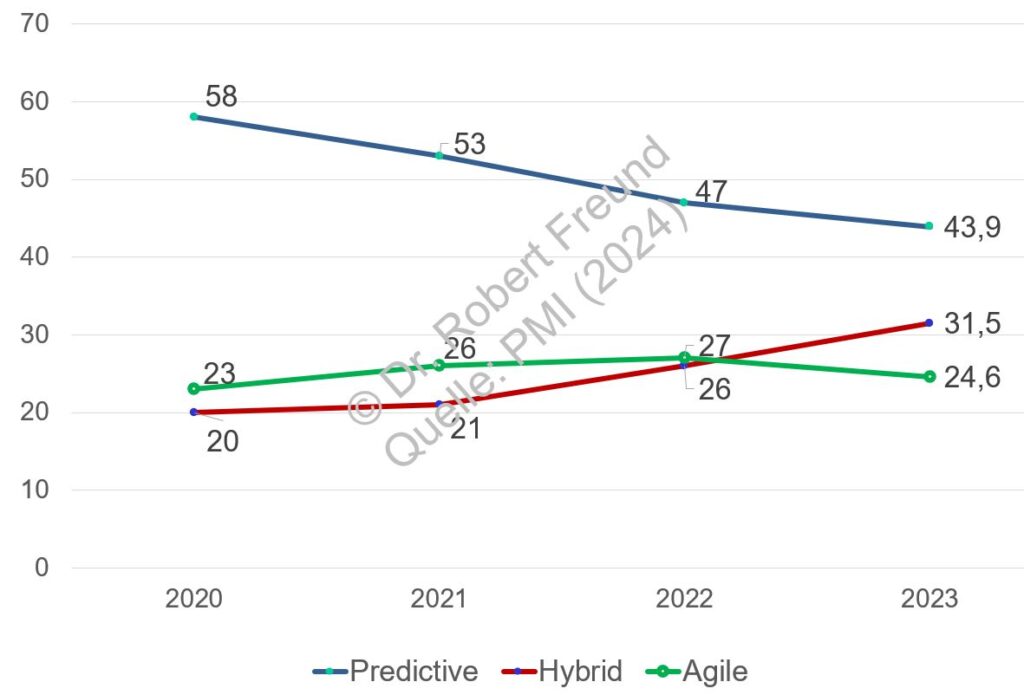
Wie bei allen neuen Ansätzen entwickelte sich daraus auch ein lohnenswertes Geschäftsmodell, von dem immer mehr Beteiligte profitieren wollten, und auch noch profitieren wollen. Nach vielen Jahren der praktischen Umsetzung stellte sich allerdings heraus, dass viele Organisationen agile Vorgehensmodelle nicht, oder nur in abgewandelter Form umsetzen, bzw. umsetzen können. Siehe dazu Hybrides Projektmanagement hat sich in vielen Unternehmen durchgesetzt (HELENA-Studie) und PMI (2024) Global Survey: Hybrides Projektmanagement wird immer wichtiger.
Es ist an der Zeit, sich die Vorteile und Nachteile von Vorgehensmodellen genauer anzusehen, um das jeweils geeignete Vorgehensmodell – bzw. deren Kombinationen – bestimmen zu können. Siehe dazu DAS Projektmanagement-Kontinuum in der Übersicht.
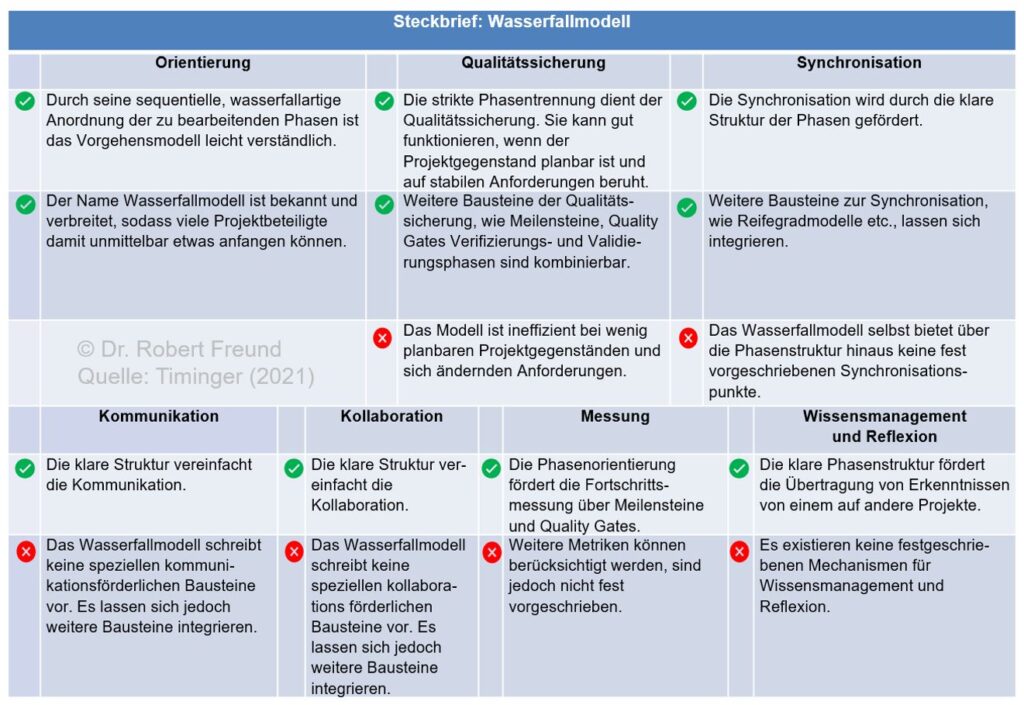
In der Abbildung sind die Vorteile und Nachteile für das Wasserfall-Modell dargestellt. Ja, das Modell ist ineffizient bei wenig planbaren Projektgegenständen und sich ändernden Anforderungen. Doch es gibt auch Vorteile, wie die klaren Strukturen, die manches vereinfachen. Schauen Sie sich die Übersicht an und bilden Sie sich ihre eigene Meinung dazu.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.