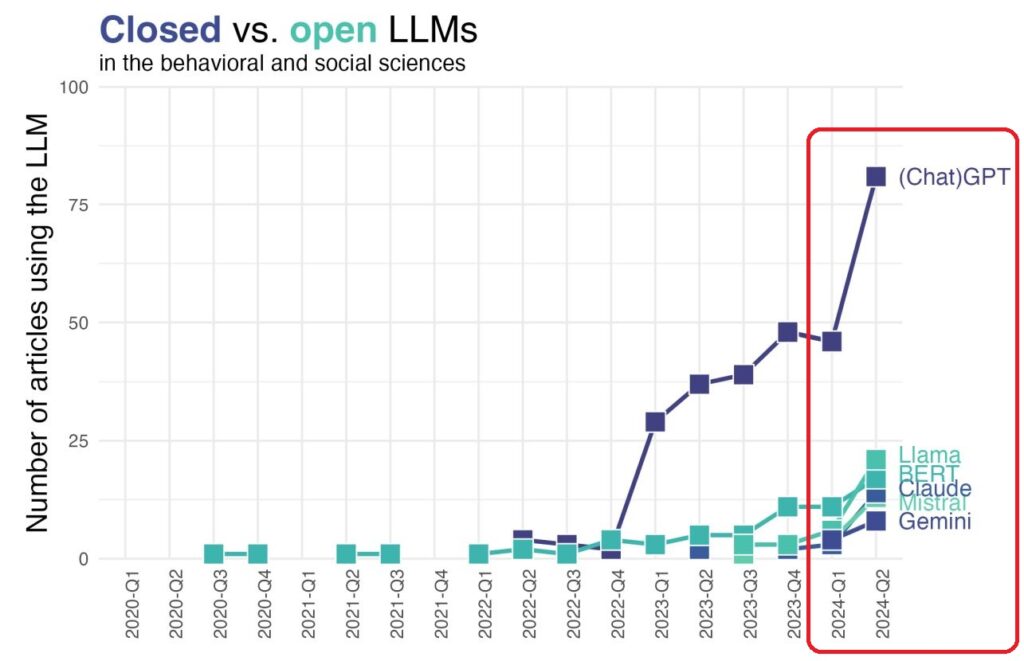
Der Begriff “Open” wird in den vielfältigsten Zusammenhängen benutzt, sodass man auch von einer entsprechenden Bewegung sprechen kann: Open Movement. Dazu zählen beispielsweise Creative Commons, Open Knowledge Foundation, Open Future, Wikimedia, die sich in diesem Jahr zu einem Austausch getroffen haben. Dabei wurde der Begriff “Open Movement” noch einmal geschärft:
“When we use the term “open movement” in this exploration, our starting point is a definition of this movement as a sum of “people, communities, and organizations who
(1) contribute to shared resources online that are available for everyone to use and reuse, and/or
(2) advocate for non-exclusive access and use of information resources.
We add to this definition those who provide tools and standards for open sharing.”
Quelle: Open movement’s common(s) causes. Report from a Wikimania 2024 side event, November 2024 | PDF.
Anhand dieser beiden Punkte kann somit abgeklärt werden, ob eine Bewegung dazu zählt, oder ob das Attribut eher für rein wirtschaftliche Interessen in einem eigenen, geschlossenen (closed) Ökosystem verwendet wird. Siehe dazu auch Open Source AI: Common Corpus als größte offene Trainingsdatenbank veröffentlicht.