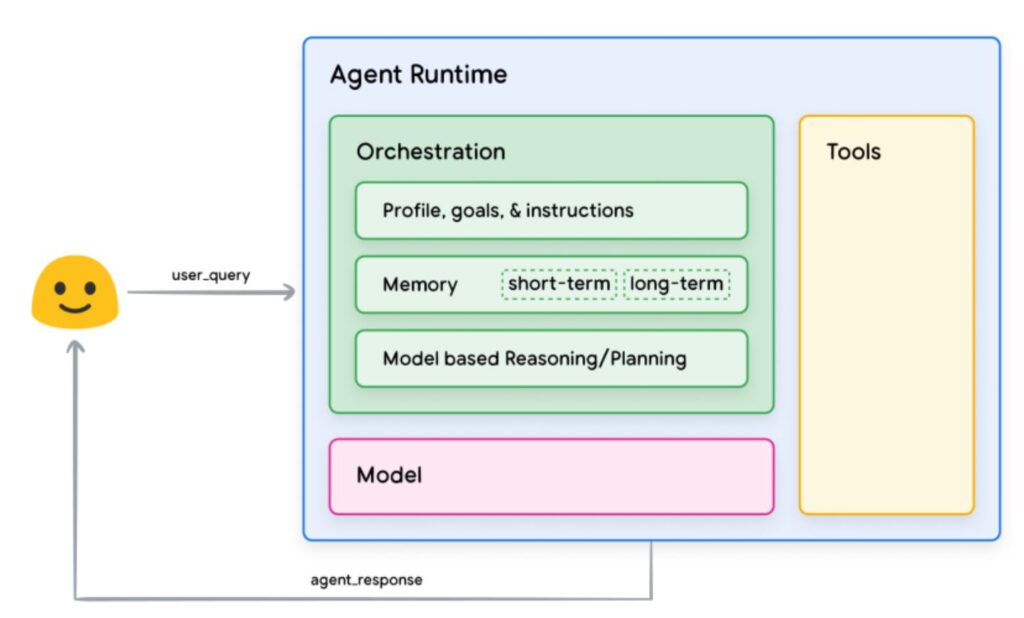
In den Diskussionen um Künstliche Intelligenz (Artificial Intelligence) werden die Tech-Riesen nicht müde zu behaupten, dass Künstliche Intelligenz die Menschliche Intelligenz ebenbürtig ist, und es somit eine Generelle Künstliche Intelligenz (AGI: Artificial General Intelligence) geben wird.
Dabei wird allerdings nie wirklich geklärt, was unter der Menschlichen Intelligenz verstanden wird. Wenn es der Intelligenz-Quotient (IQ) ist, dann haben schon verschiedene Tests gezeigt, dass KI-Modelle einen IQ erreichen können, der höher ist als bei dem Durchschnitt der Menschen. Siehe dazu OpenAI Model “o1” hat einen IQ von 120 – ein Kategorienfehler? Heißt das, dass das KI-Modell dann intelligenter ist als ein Mensch? Viele Experten bezweifeln das:
“Most experts agree that artificial general intelligence (AGI), which would allow for the creation of machines that can basically mimic or supersede human intelligence on a wide range of varying tasks, is currently out of reach and that it may still take hundreds of years or more to develop AGI, if it can ever be developed. Therefore, in this chapter, “digitalization” means computerization and adoption of (narrow) artificial intelligence” (Samaan 2024, in Werthner et al (eds.) 2024, in Anlehnung an https://rodneybrooks.com/agi-has-been-delayed/).
Es wird meines Erachtens Zeit, dass wir Menschliche Intelligenz nicht nur auf den IQ-Wert begrenzen, sondern entgrenzen. Die Theorie der Multiplen Intelligenzen hat hier gegenüber dem IQ eine bessere Passung zu den aktuellen Entwicklungen. Den Vergleich der Künstlichen Intelligenz mit der Menschlichen Intelligenz nach Howard Gardner wäre damit ein Kategorienfehler.