Wie schon in mehreren Blogbeiträgen erläutert, haben wir das Ziel, einen souveränen Arbeitsplatz zu gestalten, bei dem u.a. auch Künstliche Intelligenz so genutzt werden kann, dass alle eingegebenen und generierten Daten auf unserem Server bleiben.
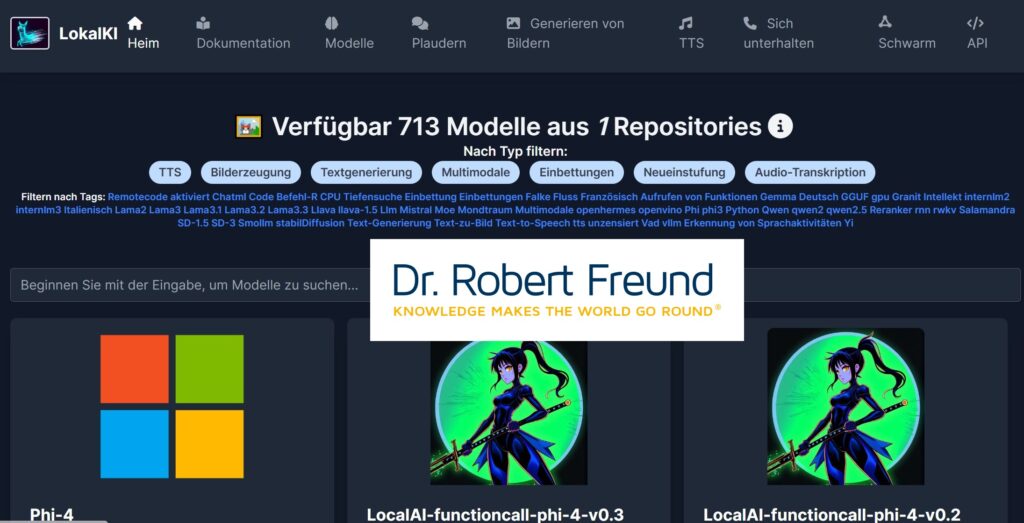
Dazu haben wir LocalAI (Open Source) auf unserem Server installiert. Damit können wir aktuell aus mehr als 700 frei verfügbaren KI-Modellen je nach Bedarf auswählen. Zu beachten ist hier, dass wir nur Open Source AI nutzen wollen. Siehe dazu auch AI: Was ist der Unterschied zwischen Open Source und Open Weights Models?
Bei den verschiedenen Recherchen sind wir auch auf OLMo gestoßen. OLMo 2 ist eine LLM-Familie (Large Language Models), die von Ai2 – einer Not for Profit Organisation – entwickelt wurde und zur Verfügung gestellt wird:
“OLMo 2 is a family of fully-open language models, developed start-to-finish with open and accessible training data, open-source training code, reproducible training recipes, transparent evaluations, intermediate checkpoints, and more” (Source: https://allenai.org/olmo).
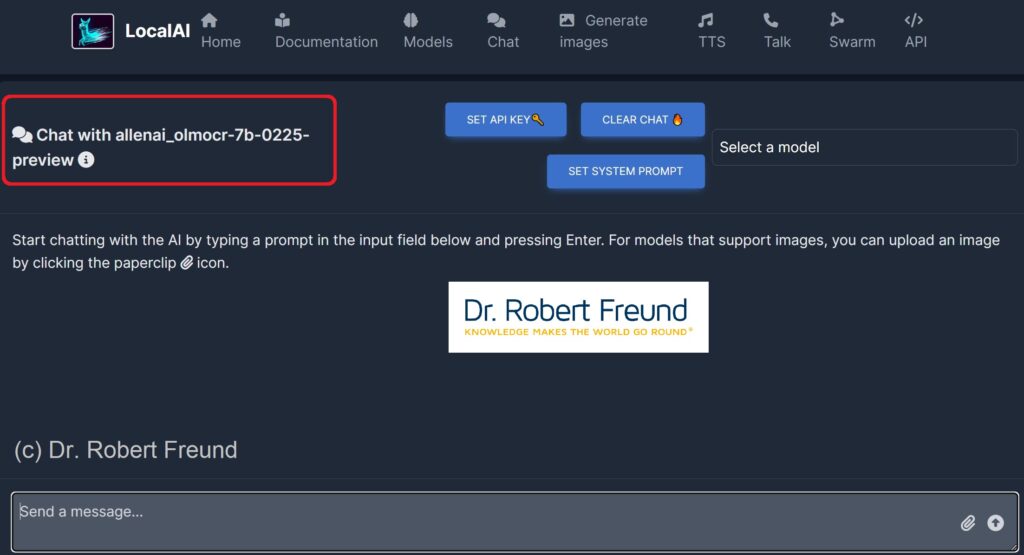
Unter den verschiedenen Modellen haben wir uns die sehr spezielle Version allenai_olmocr-7b-0225 in unserer LocalAI installiert – siehe Abbildung.
“olmOCR is a document recognition pipeline for efficiently converting documents into plain text” (ebd.)
Siehe dazu auch Efficient PDF Text Extraction with Vision Language Models.
Selbstverständlich werden wir demnächst auch noch andere Möglichkeiten aus der OLMo-Familie testen und Erfahrungen sammeln.