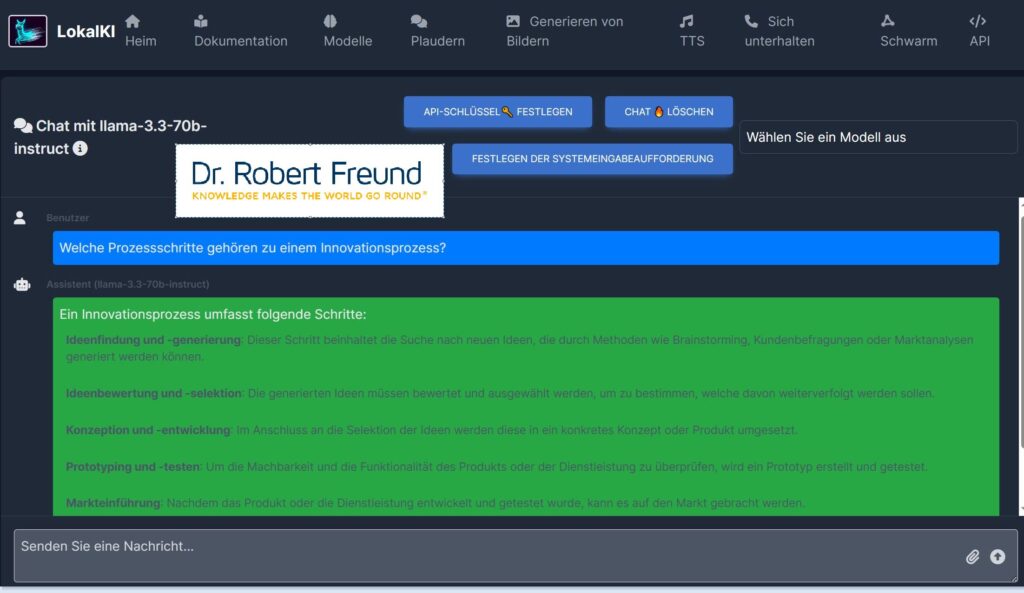
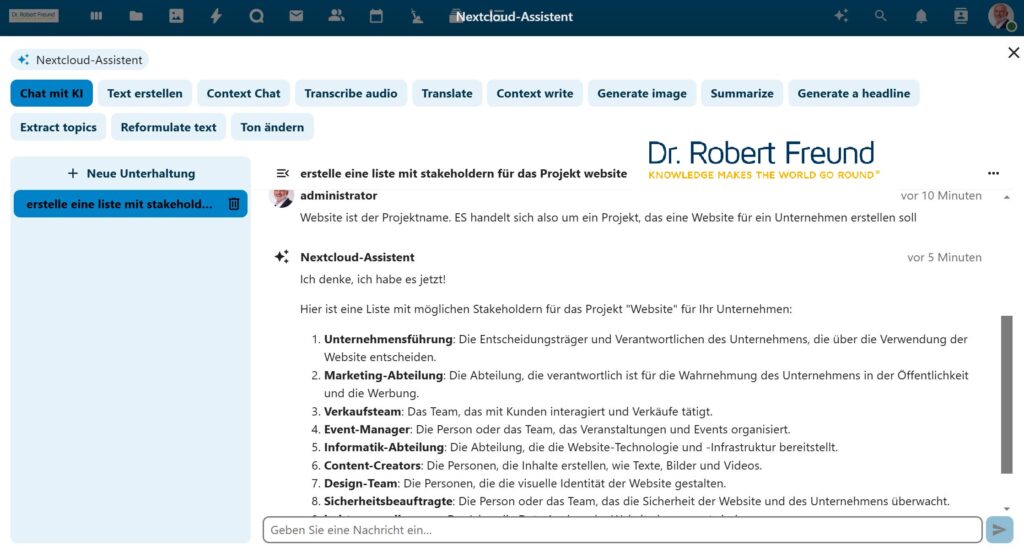
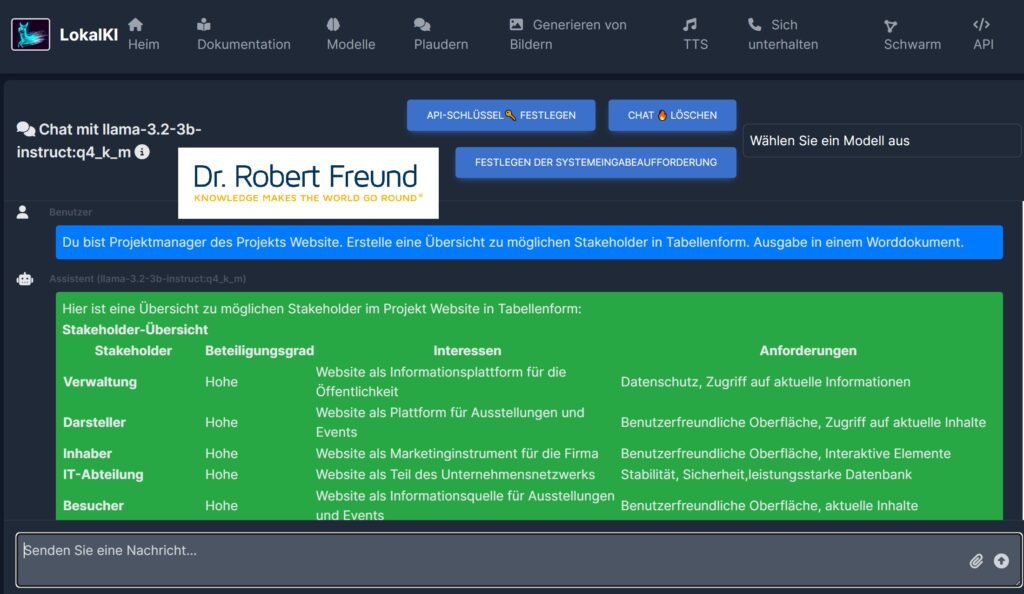
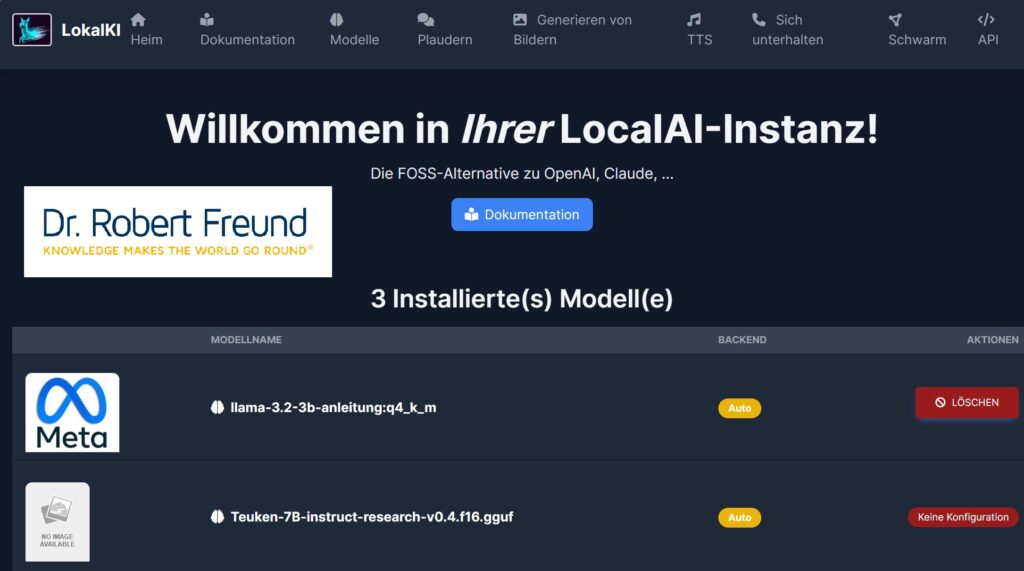
In verschiedenen Beiträgen habe ich schon erläutert, dass sich Open Source AI und Closed Source AI unterscheiden. Die bekannten Closed Source AI Modelle wie z.B. ChatGPT von (OpenAI) sind beispielsweise nicht wirklich Open Source sind, da dsolche Modelle intransparent sind und den eigentlichen Zweck haben, wirtschaftliche Gewinne zu generieren – koste es was es wolle. Siehe dazu Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.
Zwischen diesen beiden Polen Open Source AI und Closed Source AI gibt es allerdings – wie immer – ein Kontinuum von weiteren Möglichkeiten. Beispielsweise sind LLama, Mistral und Gemma nicht so ohne weiteres den beiden Extremen zuzuordnen, da diese Modelle teilweise offen sind. Solche Modelle werden Open Weights Models genannt:
“As a result, the term “Open Source” has been used to describe models with various levels of openness, many of which should more precisely be described as “open weight” models. Among the Big AI companies, attitudes towards openness vary. Some, like OpenAI or Anthropic, do not release any of their models openly. Others, like Meta, Mistral or Google, release some of their models. These models — for example, Llama, Mistral or Gemma — are typically shared as open weights models” (Tarkowski, A. (2025): Data Governance in Open Source AI. Enabling Responsible and Systemic Access. In Partnership with the Open Source Initiative).
Warum nur werden solche Modelle angeboten? Der Grund kann sein, dass man mit dieser Strategie versucht, dem Regulierungsbestreben z.B. der Europäischen Union entgegenzuwirken. Ich hoffe, dass das nicht funktioniert und Big Tech gezwungen wird, sich an die Spielregeln in der Europäischen Union zu halten. Aktuell sieht es so aus, dass die neue Regierung der USA die Europäische Union auch bei diesem Thema vor sich hertreiben möchte.