Wie Sie wissen, haben wir eine lokale KI (LokalKI) oder LocalAI installiert. Siehe dazu Free Open Source Software (FOSS): Eigene LocalAI-Instanz mit ersten drei Modellen eingerichtet.
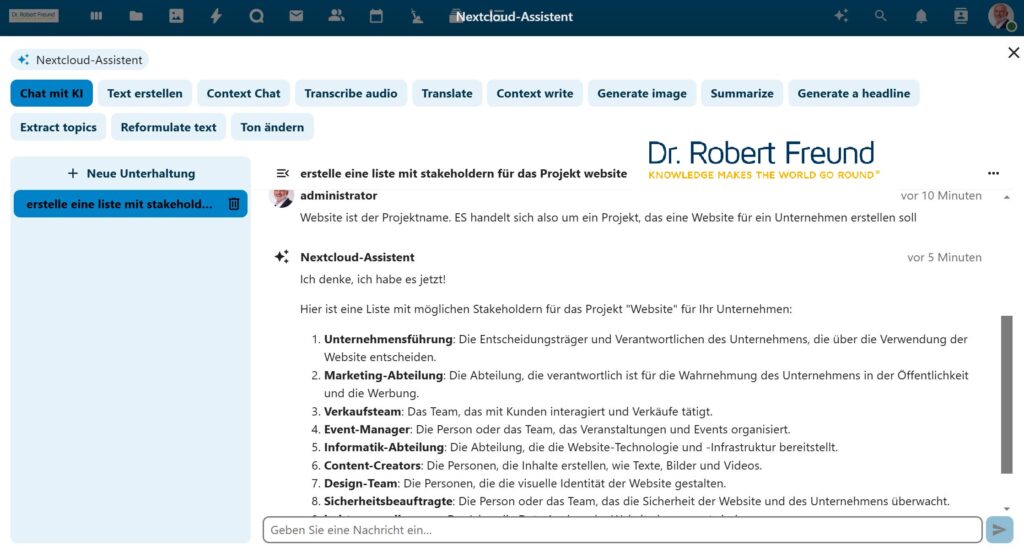
In unserer Kollaborationsplattform Nextcloud (Open Source) kann an jeder beliebigen Stelle der Nextcloud-Assistent aufgerufen werden. Wie in der Abbildung zu sehen ist, ergeben sich hier viele Möglichkeiten, die auch mit lokalen Large Language Models (LLM) verknüpft sind.
In dem Beispiel ist CHAT MIT KI angewählt. Diese Funktion ist in unserer LocalAI mit Llama 3.2 (LLM) verknüpft.
Als Prompt habe ich zum Test einfach “Erstelle eine Liste mit Stakeholdern für das Projekt Website” eingegeben.
Es kam zu einer Nachfrage, die ich beantwortet habe. Anschließend wurde eine durchaus brauchbare Liste möglicher Stakeholder für ein Projekt “Website” ausgegeben.
Nach verschiedenen kleinen Einstellungen am Server waren die Antwortzeiten sehr gut.
Der große Vorteil bei dieser Arbeitsweise ist allerdings: Alle Daten bleiben auf unserem Server – LocalAI eben.

