Digitale Souveränität fängt damit an, sich von propritärer Software unabhängiger zu machen. Proprietäre Software ist Software, deren Quellcode nicht öffentlich ist, und die Unternehmen gehört (Closed Software). Dazu zählen einerseits die verschiedenen Anwendungen von Microsoft, aber auch die von Google oder ZOHO usw.
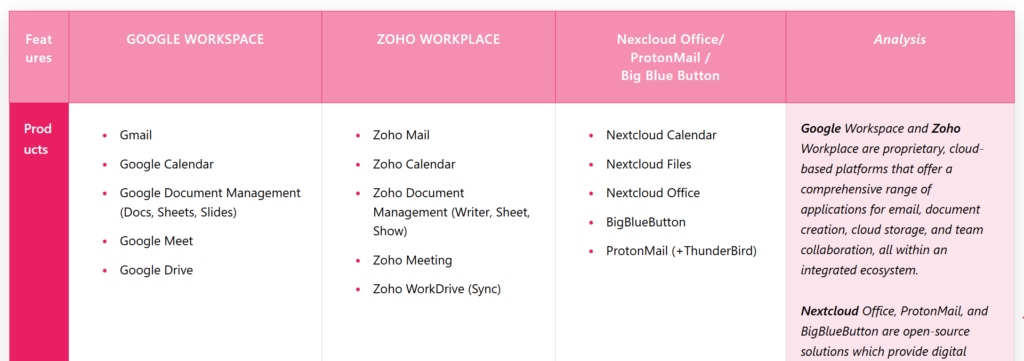
Demgegenüber gibt es in der Zwischenzeit leistungsfähige Open Source Software. Die indische Organisation SFLC hat am 11. November eine Übersicht veröffentlicht, die Google Workplace, ZOHO Workplace und Nextcloud Office/ProtonMail/BigBlueButton gegenüberstellt – die Abbildung zeigt einen Ausschnitt aus der Tabelle, die in diesem Beitrag zu finden ist.
„The purpose of this comparison is to assess the different approaches, features, and trade-offs each solution presents and to help organizations make informed decisions based on their operational requirements, technical capabilities, and priorities around privacy, flexibility, and cost“ (ebd.).
Wir nutzen seit einiger Zeit Nextcloud mit seinen verschiedenen Möglichkeiten, inkl. Nextcloud Talk (Videokonferenzen), sodass BigBlueButton nicht separat erforderlich ist.
Darüber hinaus nutzen wir LocalAI über den Nextcloud Assistenten, haben OpenProject integriert und erweitern diese Möglichkeiten mit Langflow und Ollama, um KI-Agenten zu entwickeln.
Alles basiert auf Open Source Software, die auf unseren Servern laufen, sodass auch alle Daten auf unseren Servern bleiben – ganz im Sinne einer stärkeren Digitalen Souveränität.