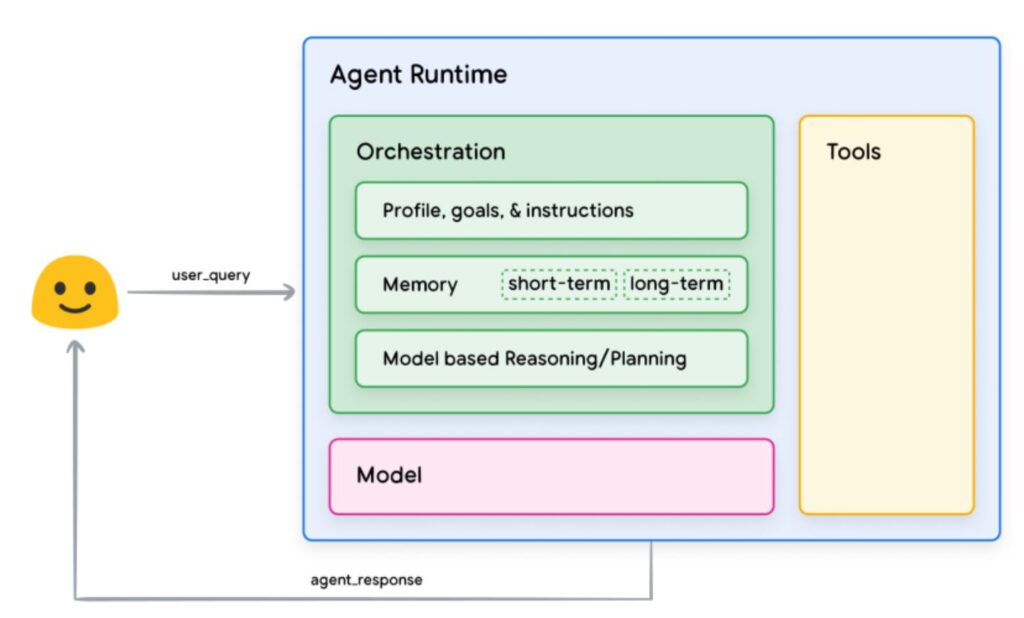
In dem Blogbeitrag Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data hatte ich schon erläutert, wie wichtig es ist, dass sich Organisationen und auch Privatpersonen nicht nur an den bekannten AI-Modellen der Tech-Giganten orientieren. Ein wichtiges Kriterien sind die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen.
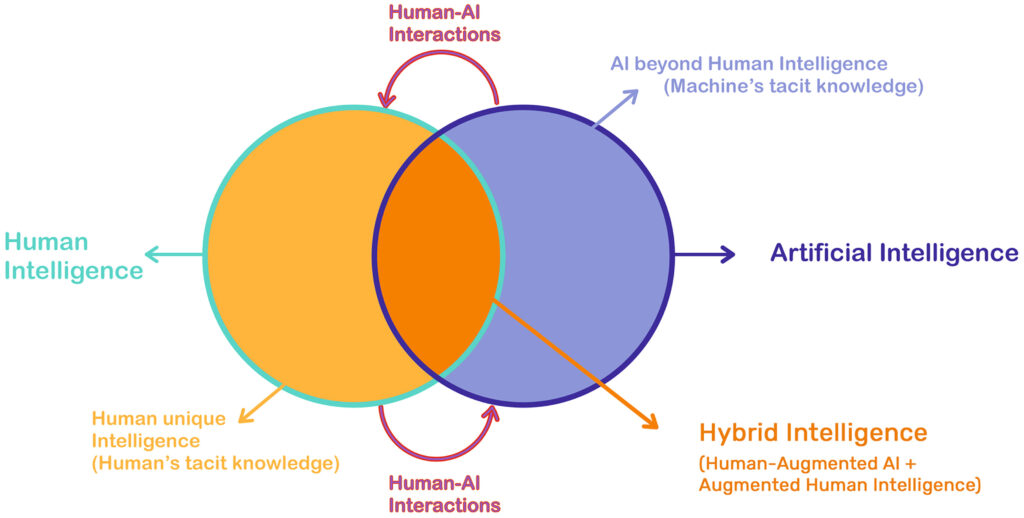
In Europa haben wir gegenüber China und den USA in der Zwischenzeit ein eigenes Verständnis von der gesellschaftlichen Nutzung der Künstlichen Intelligenz entwickelt (Blogbeitrag). Dabei spielen die technologische Unabhängigkeit (Digitale Souveränität) und die europäische Kultur wichtige Rollen.
Die jeweiligen europäischen Kulturen drücken sich in den verschiedenen Sprachen aus, die dann auch möglichst Bestandteil der in den KI-Modellen genutzten Trainingsdatenbanken (LLM) sein sollten – damit meine ich nicht die Übersetzung von englischsprachigen Texten in die jeweilige Landessprache.
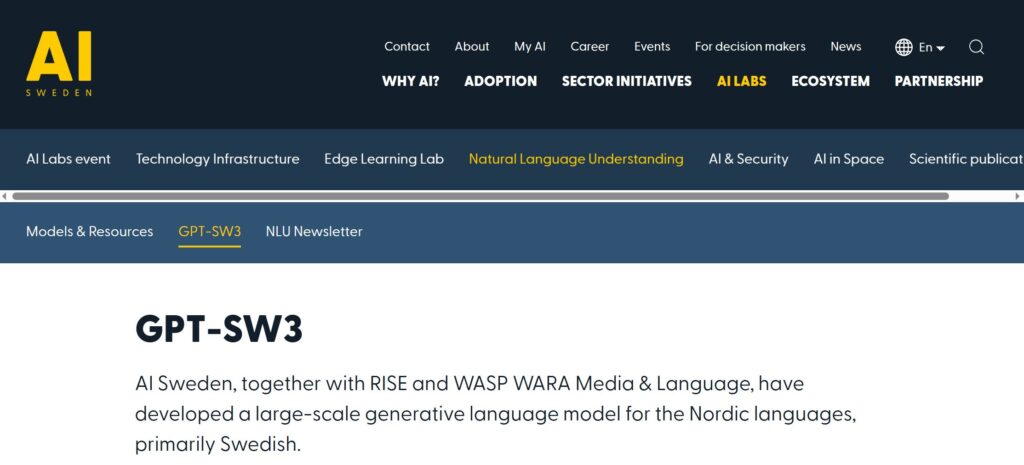
Ein Beispiel für so eine Entwicklung ist AI SWEDEN mit dem veröffentlichten GPT-SW3 (siehe Abbildung). Das LLM ist im Sinne der Open Source Philosophie (FOSS: Free Open Source Software) transparent und von jedem nutzbar – ohne Einschränkungen.
“GPT-SW3 is the first truly large-scale generative language model for the Swedish language. Based on the same technical principles as the much-discussed GPT-4, GPT-SW3 will help Swedish organizations build language applications never before possible” (Source).
Für schwedisch sprechende Organisationen – oder auch Privatpersonen – bieten sich hier Möglichkeiten, aus den hinterlegten schwedischen Trainingsdaten den kulturellen Kontext entsprechend Anwendungen zu entwickeln. Verfügbar ist das Modell bei Huggingface.