Die aktuellen Entwicklungen zeigen unsere (europäische) digitale Abhängigkeit von amerikanischen Tech-Riesen. Ob es sich um Starlink, ein Unternehmen von Elon Musk, oder um OpenAI (dominiert von Microsoft), Amazon Cloud, Google usw. handelt, überall haben sich die amerikanischen Tech-Unternehmen in Europa durchgesetzt.
Immer mehr Privatpersonen, Unternehmen und Verwaltungen überlegen allerdings aktuell, ob es nicht besser ist, europäische Alternativen zu nutzen, um die genannte digitale Abhängigkeit zu reduzieren.
Die Website European alternatives for digital products hat nun angefangen, verschiedene europäische Alternativen zu den etablierten Angeboten aufzuzeigen. Die Übersicht ist nach verschiedenen Kategorien gegliedert. Die Website ist eine Initiative eines österreichischen Softwareentwicklers und steht erst am Anfang.
Insgesamt kann diese Website in die Initiative Sovereign Workplace eingeordnet werden, an dem wir uns auch schon länger orientieren. Dabei werden Vorschläge gemacht, welche Anwendungen auf Open Source Basis geeignet erscheinen.
Immer mehr Privatpersonen und Organisationen realisieren, dass die populären Trainingsdaten (LLM: Large Language Models) für ChatGPT von OpanAI, oder auch Gemini von Google usw., so ihre Tücken haben können, wenn es beispielsweise im andere oder um die eigenen Urheberrechte geht. In diesem Punkt unterscheiden wir uns in Europa durchaus von den US-amerikanischen und chinesischen Ansätzen. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich. Darüber hinaus liegen die Daten der bekannten (closed source) LLMs zu einem überwiegenden Teil in englischer oder chinesischer Sprache vor.
“Multilingual, open source models for Europe – instruction-tuned and trained in all 24 EU languages…. Training on >50% non English Data. (…) This led to the creation of a custom multilingual tokenizer” (ebd.).
Neben der freien Verfügbarkeit (Open Source AI) (via Hugging Face) ist somit ein großer Pluspunkt, dass eine große Menge an Daten, nicht englischsprachig sind. Das unterscheidet dieses Large Language Model (LLM) sehr deutlich von den vielen englisch oder chinesisch dominierten (Closed Source) Large Language Models.
Insgesamt halte ich das alles für eine tolle Entwicklung, die ich in der Geschwindigkeit nicht erwartet hatte!
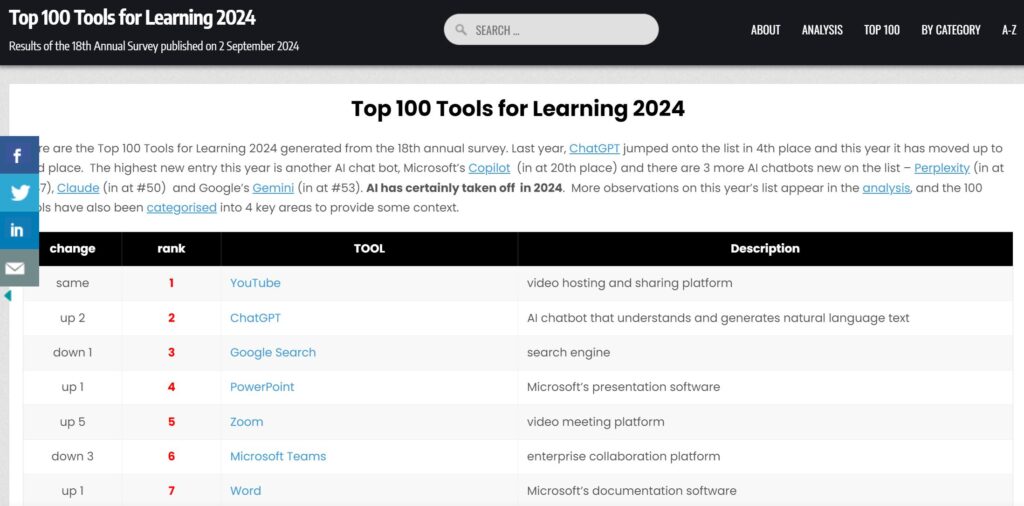
Es ist nicht verwunderlich, dass immer mehr KI-Anwendungen in der Liste der 100 Tools for Learning auftauchen. ChatGPT ist vom 4. auf den 2. Platz vorgerückt und weitere KI-Copilots tauchen in der Liste auf, bzw. rücken auch in den Platzierung vor. Es sieht so aus, als ob immer mehr KI-Anwendungen für Lernprozesse genutzt werden.
Es ist daher für viele an der Zeit, sich mit den Möglichkeiten und Beschränkungen von KI-Anwendungen bei Lernprozessen zu befassen. Am besten geht das in Unternehmen natürlich im Prozess der Arbeit: Kompetenzentwicklung im Prozess der Arbeit.
Ja, es gibt ChatGPT von OpenAI, Bard von Google usw. usw. und ich muss sagen, dass die Ergebnisse z.B. von ChatGPT schon beeindruckend sind. Warum sollte man sich dennoch mit Alternatiuven befassen? Es ist relativ einfach, denn manche Unternehmen verbieten den Einsatz von diesen Systemen. Den Grund liefert die Google-Mutter Alphabet selbst: Bard: Google warnt Mitarbeiter vor der Nutzung des eigenen Chatbots. Hier ein Auszug:
Ausgerechnet die Google-Mutter Alphabet warnt seine Mitarbeiter vor der Nutzung generativer KI – inklusive des hauseigenen Chatbots Bard. Speziell Ingenieure sollten weder Code zur Fehleranalyse in trainierten Sprachmodelle eingeben, noch die ausgegebenen Zeilen nutzen. In einem am 1. Juni aktualisierten Datenschutzhinweis von Google heißt es Reuters zufolge: “Fügen Sie keine vertraulichen oder sensiblen Informationen in Ihre Bard-Konversationen ein”. (ebd.)
Die Entwicklungen von NEXTCLOUD könnten in diesem Zusammenhang interessant werden, da es auf Open-Source-Basis die in KI-Anwednungen generieten Daten in ihrer eigenen geschützten Cloud behält. Wie kann man sich das vorstellen? Wie Sie wissen, haben wir Nextcloud als Open-Source-Anwendung für Cloudanwendungen auf unseren Servern installiert. Dabei war bisher der Schwerpunkt auf der Weiterentwicklung zu einer integrierten Kollaborationsplattform auf Open-Source-Basis.
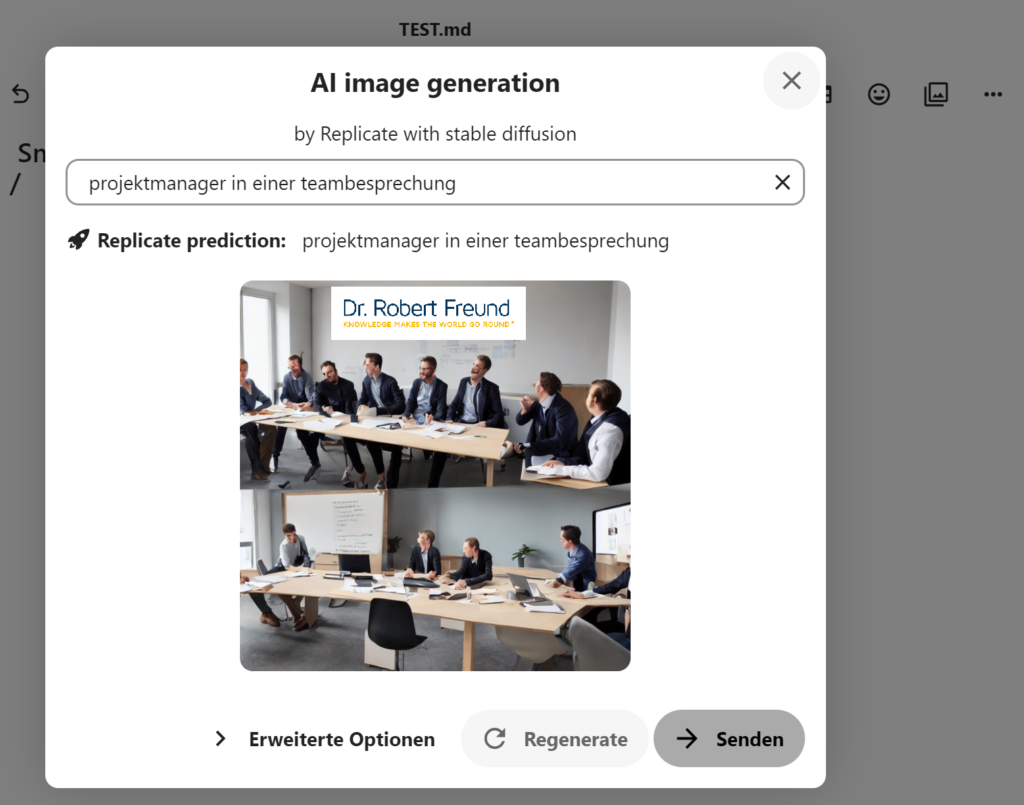
Seit Nextcloud Hub 4 gibt es die Möglichkeit, Apps zur Künstlicher Intelligenz (KI; AI: Articicial Intelligence) in Dateien aufzurufen. In dem Beispiel (Screenshot) haben wir eine Textdatei (TEXT.md) geöffnet, und mit dem Smart Picker (“/”) verschiedene KI-Anwendungen geöffnet. Eine davon basiert auf Stabe Diffusion und kann Bilder auf Basis einer Eingabe (Prompt) generieren. Beispielhaft haben wir in der vorgesehenen Zeile “Projektmanager in einer Teambesprechung” eingegeben. Das Ergebnis sehen Sie in dem Screenshot. Die generierten Daten und die Prompts bleiben alle auf unseren Servern. In einem der nächsten Blogbeiträge, werde ich eine weitere KI-Anwendung innerhalt von NEXTCLOUD vorstelen.
Ziel von Nextcloud ist es, in Zukunft immer mehr AI-Anwendungen integriert anzubieten, wobei die AI-Apps auch ethisch eingeordnet werden sollen. Basis dafür ist eine Ampelfunktion. Siehe dazu Nextcloud Hub 4 mit “ethical AI” Integration – Open Source.
Wir werden in der nächsten Zeit immer mehr AI-Apps in Nextcloud in Bezug zu unseren Themen wie z.B. Projektmanagement ausprobieren, und so wichtige Erfahrungen sammeln.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
TensorFlow ist Google´s Open Source Software Library for Maschine Learning. Seit 09.11.2015 stehen die Möglichkeiten des Deep Learning allen zur Verfügung, die daraus Anwendungen oder auch innovative Geschäftsmodelle entwickeln wollen. Damit steht TensorFlow in direkter Konkurrenz zu IMB´s Warson Projekt, dass seine API auch freigegeben hat. Mal sehen, wo das schnellste und innovativste Ökosystem für entsprechende Anwendungen entsteht. Ich vermute eher bei Google – bin mir aber nicht sicher. Da ich mich in meiner Special Keynote auf der Weltkonferenz MCPC 2015 in Monteeal mit Cognitive Computing befasst habe, bin ich an dieser Entwicklung stark interessiert. Siehe dazu auch Freund, R. (2015): Cognitive Computing and Managing Complexity in Open innovation Model, MCPC 2015 proceedings. Natürlich gehen wir auf diese ntwicklungen auch in dem von uns entwickelten Blended Learning Lehrgang Innovationsmanager (IHK) ein. Informationen finden Sie dazu auf unserer Lernplattform.
Google is soliciting proposals for pioneering research related to the Internet of Things. This is a crossdisciplinary expedition intended to address the complex challenges and opportunities before us as we explore the next generation of systems, services and Internetconnected devices. Open innovation is a core principle of this program to make the Internet of Things a reality for everybody.
Dabei bezieht man sich bei der Quellenangabe ausdrücklich nur auf Chesbrough (2003). Das verwundert etwas, da im Text später ausdrucklich User Innovation angesprochen werden, die möglicherweise nicht nur auf Unternehmen bezigen sind. Wenn dem so ist, wäre ein zusätzlicher Hinweis auf Eric von Hippel gut, der schon in den 80er Jahren auf dieses Phänomen aufmerksam gemacht, und in seinem Buch aus dem Jahr 2005 “Democratizing Innovation” beschriben hat. Aber so genau will man es wohl hier nicht nehmen – schade.
Aus der Zusammenarbeit der EPO (European Patent Office) mit Google hat sich ein interessantes Tool zur Übersetzung von Patenten in immerhin 14 Sprachen ergeben: “Patent Translate now covers translations between English and fourteen other languages, namely Chinese, Danish, Dutch, German, Finnish, French, Greek, Hungarian, Italian, Norwegian, Polish, Portuguese, Spanish and Swedish. More languages will be added in the coming years.” Durch diesen kostenlosen Service wird es nun leichter, Patente zu analysieren. Das ist eine Chance, birgt allerdings auch das Risiko, technisches Wissen – gebunden in Patenten – zu erschließen. Jede Neuerung ist ambivalent, bietet somit Vorteile und Nachteile gleichermaßen. Doch mittel- und langfristig schätze ich, dass diese Art von Offentheit/Transparenz, mehr nutzt als schadet.
Translate »
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK