Wenn Sie die bekannten Trainingsmodelle (LLM: Large Language Modells) bei ChatGPT (OpenAI), Gemini (Google) usw. nutzen, werden Sie sich irgendwann als Privatperson, oder auch als Organisation Fragen, was mit ihren eingegebenen Texten (Prompts) oder auch Dateien, Datenbanken usw. bei der Verarbeitung Ihrer Anfragen und Aufgaben passiert.
Antwort: Das weiß keiner so genau, da die KI-Modelle nicht offen und transparent sind.
Ein wirklich offenes und transparentes KI-Modell orientiert sich an den Vorgaben für solche Modelle, die in der Zwischenzeit veröffentlicht wurden. Siehe dazu beispielsweise Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.
Um die eigene Souveränität über unsere Daten zu erlangen, haben wir seit einiger Zeit angefangen, uns Stück für Stück von kommerziellen Anwendungen zu lösen. Angefangen haben wir mit NEXTCLOUD, das auf unserem eigenen Server läuft. NEXTCLOUD Hub 9 bietet die Möglichkeiten, die wir alle von Microsoft kennen.
Dazu kommt in der Zwischenzeit auch ein NEXTCLOUD-Assistent, mit dem wir auch KI-Modelle nutzen können, die auf unserem Serverlaufen. Dieses Konzept einer LOCALAI – also einer lokal angewendeten KI – ist deshalb sehr interessant, da wir nicht nur große LLM hinterlegen, sondern auch fast beliebig viele spezialisierte kleinere Trainingsmodelle (SML: Small Language Models) nutzen können. Siehe dazu Free Open Source Software (FOSS): Eigene LocalAI-Instanz mit ersten drei Modellen eingerichtet.
In dem Blogbeitrag LocalAI (Free Open Source Software): Chat mit KI über den Nextcloud-Assistenten haben wir dargestellt, wie im NEXTCLOUD Assistenten mit einer lokalen KI gearbeitet werden kann.
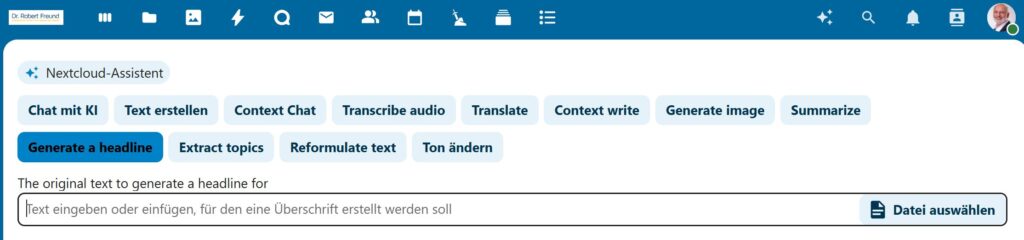
Wie in der Abbildung zu sehen, können wir mit dem NEXTCLOUD Assistenten auch Funktionen nutzen, und auch eigene Dateien hochladen. Dabei werden die Dateien auch mit Hilfe von dem jeweils lokal verknüpften lokalen KI-Modell bearbeitet. Alle Daten bleiben dabei auf unserem Server – ein unschätzbarer Vorteil.
Die Kombination von LOCALAI mit eigenen Daten auf dem eigenen Server macht dieses Konzept gerade für Kleine und Mittlere Unternehmen (KMU) interessant.

