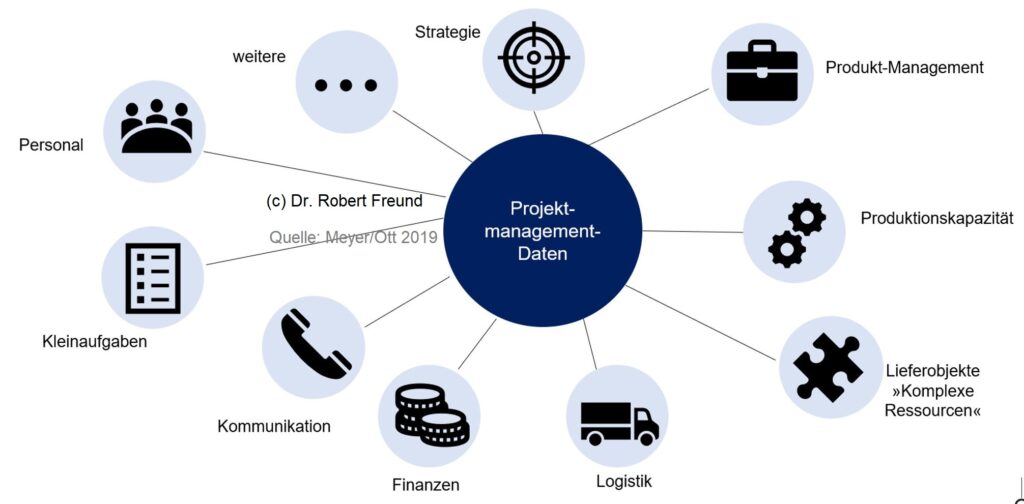
In der Vergangenheit wurden z.B. im Projektmanagement nach und nach immer mehr digitale Tools verwendet. Zunächst waren das Anwendungen aus dem Office-Paket, dann kam Microsoft Project hinzu und in der Zwischenzeit gibt es von Microsoft eine integrierte Kollaborationsplattform (Sharepoint, Microsoft Project Online, Teams, Office Apps etc.), die das Arbeiten in Projekten effektiver/produktiver macht. Der nächste Booster wird Künstliche Intelligenz (KI) sein, die über OpenAI als KI-Assistent Projektmanagement-Prozesse unterstützen wird. Andere Tech-Größen wie Google, Facebook und Apple werden diesem Beispiel folgen. Der Vorteil des von Microsoft etablierten IT-Ökosystems ist, dass sich Mitarbeiter, Teams, Organisationen – ja sogar ganze staatliche Verwaltungsstrukturen – an die Logik von Microsoft angepasst haben. Ob das gut ist, kann allerdings infrage gestellt werden. Siehe dazu Warum geschlossene Softwaresysteme auf Dauer viel Zeit und viel Geld kosten.
Dieser Lock-in führt zu einer Pfadabhängigkeit und macht es für Alternativen schwer – Alternativen wie z.B. Open Source Anwendungen. Denn obwohl berechtigte Gründe gegen ein kommerzielles IT-Ökosystem sprechen, bleiben viele Organisationen bei den etablierten IT-Strukturen, da diese Organisationen die Kosten für einen Wechsel (Switching Costs) scheuen. Es wird in Zukunft somit um die Frage gehen, was teurer ist: Das Festhalten an etablierten IT-Strukturen oder ein Wechsel zu Open Source Anwendungen, die einen Souveränen Arbeitsplatz auf Open Source Basis garantieren. Dazu zählt auch, die Verwaltung und die Nutzen der eigenen Daten auf den eigenen Servern, denn Daten sind das neue Öl. Siehe dazu auch Was wäre wenn jeder über seine Daten selbst entscheiden könnte?
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen Projektmanager/in (IHK) und Projektmanager/in AGIL (IHK). Informationen dazu, und zu aktuellen Terminen, finden Sie auf unserer Lernplattform.