Wir sind uns alle einig, dass Daten eine bedeutende Ressource für einzelne Personen, Unternehmen, Organisationen und ganze Gesellschaften darstellen. Einerseits müssen Daten offen verfügbar sein, andererseits allerdings auch geschützt werden. Insofern macht es Sinn, verschiedene Kategorien für Daten zu unterscheiden:
“Open data: data that is freely accessible, usable and shareable without restrictions, typically under an open license or in the Public Domain36 (for example, OpenStreetMap data);
Public data: data that is accessible to anyone without authentication or special permissions
(for example, Common Crawl data). Note that this data can degrade as web content
becomes unavailable;
Obtainable data: data that can be obtained or acquired through specific actions, such as
licensing deals, subscriptions or permissions (for example, ImageNet data);
Unshareable non-public data: data that is confidential or protected by privacy laws,
agreements or proprietary rights and cannot be legally shared or publicly distributed”
(Tarkowski, A. (2025): Data Governance in Open Source AI. Enabling Responsible and Systemic Access. In Partnership with the Open Source Initiative).
Es zeigt sich, dass es viele frei verfügbare Daten gibt, doch auch Daten, die geschützt werden sollten.
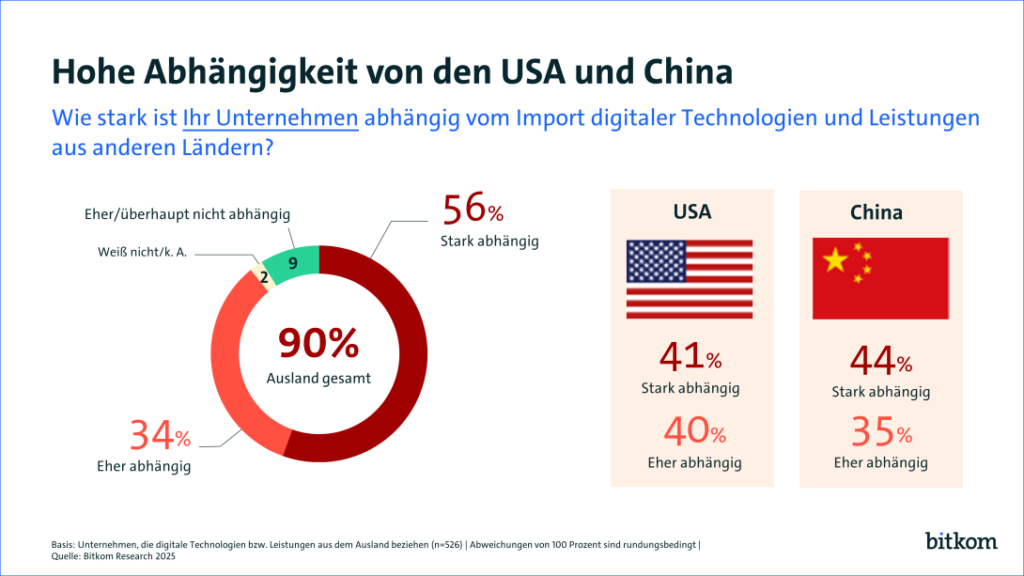
Die amerikanischen Tech-Konzerne möchten alle Daten für ihre Trainingsdatenbanken (LLM: Large Language Models) kostenlos nutzen können. Das Ziel ist hier, die maximale wirtschaftliche Nutzung im Sinne einiger weniger Großkonzerne. Dabei sind die Trainingsdaten der bekannten KI-Modelle wie ChatGPT etc. nicht bekannt/transparent. Die Strategie von Big-Tech scheint also zu sein,: Alle Daten “abgreifen” und seine eigenen Daten und Algorithmen zurückhalten. Ein interessantes Geschäftsmodell, dass sehr einseitig zu sein scheint.
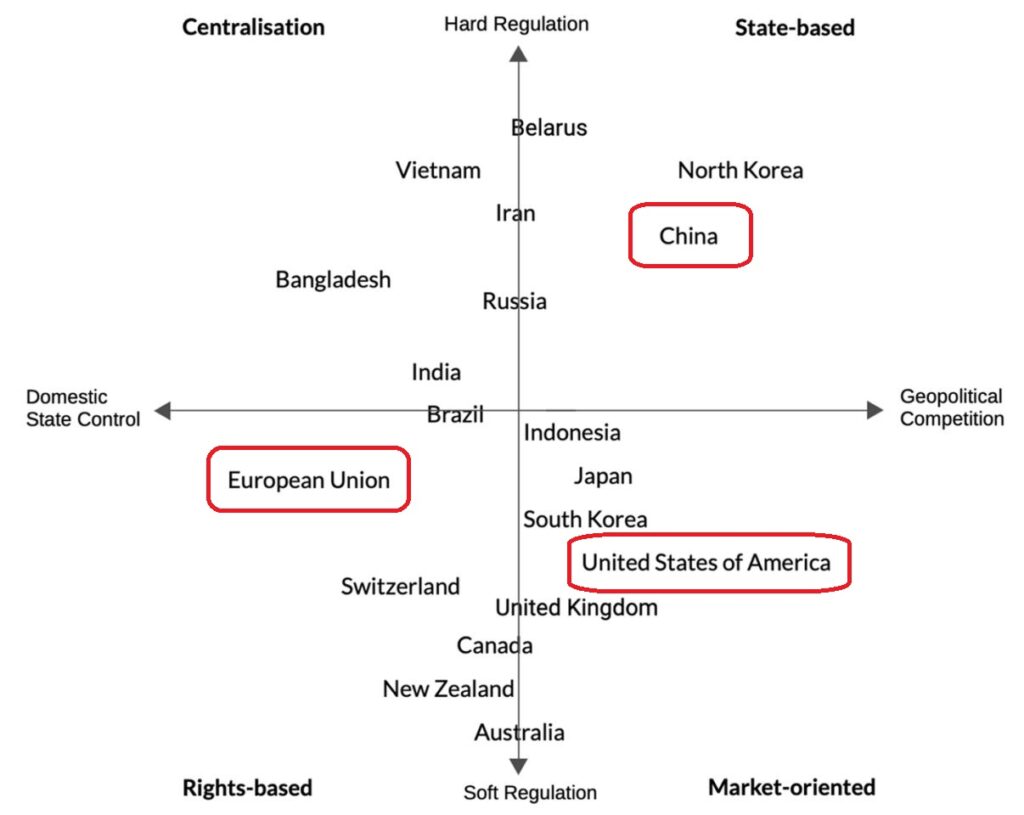
Bei der chinesische Perspektive auf Daten liegt der Schwerpunkt darauf, mit Hilfe aller Daten politische Ziele der Einheitspartei zu erfüllen. Daran müssen sich alle Bürger und die Unternehmen – auch die KI-Unternehmen – halten.
In Europa versuchen wir einen hybriden Ansatz zu verfolgen. Einerseits möchten wir in Europa Daten frei zugänglich machen, um Innovationen zu fördern. Andererseits wollen wir allerdings auch, dass bestimmte Daten von Personen, Unternehmen, Organisationen und Öffentlichen Verwaltungen geschützt werden.
An dieser Stelle versucht die aktuelle amerikanische Regierung, Druck auf Europa auszuüben, damit Big-Tech problemlos an alle europäischen Daten kommen kann. Ob das noch eine amerikanische Regierung ist, oder nicht schon eine kommerziell ausgerichtete Administration wird sich noch zeigen. Das letzte Wort werden wohl die Gerichte in den USA haben.
Ich hoffe, dass wir in Europa unseren eigenen Weg finden, um offene Daten in großem Umfang verfügbar zu machen, und um gleichzeitig den Schutz sensibler Daten zu gewährleisten.
Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich.