Was passiert eigentlich mit meinen Daten, wenn ich Künstliche Intelligenz nutze? Bei Anweisungen (Prompts) an das jeweilige KI-Modell ist oft nicht klar, was mit den Daten passiert, da viele der bekannten Modelle – wie beispielsweise ChatGPT – Closed Source Models, also nicht transparent sind.
Gerade wenn es um persönliche Daten geht, ist das unangenehm. Es ist daher sehr erfreulich, dass die Entwicklung eines Tools, dass die privaten Daten schützt öffentlich gefördert wurde und als Open Source Anwendung frei zur Verfügung steht.
“Mit der kostenlosen Anwendung Private Prompts bleiben deine Daten dort, wo sie hingehören – bei dir auf deinem Rechner. Die Entwicklung von Private Prompts wird im Zeitraum 1.9.2024-28.02.2025 gefördert durch das Bundesministerium für Bildung und Forschung und den Prototype Fund (Förderkennzeichen 01IS24S44)” (Quelle: https://www.privateprompts.org/).
Wir gehen noch einen Schritt weiter, in dem wir LocalAI auf unserem Server installiert haben. Wir nutzen dabei verschiedene Modelle, die als Open Source AI bezeichnet werden können. Siehe dazu
In verschiedenen Beiträgen habe ich schon erläutert, dass sich Open Source AI und Closed Source AI unterscheiden. Die bekannten Closed Source AI Modelle wie z.B. ChatGPT von (OpenAI) sind beispielsweise nicht wirklich Open Source sind, da dsolche Modelle intransparent sind und den eigentlichen Zweck haben, wirtschaftliche Gewinne zu generieren – koste es was es wolle. Siehe dazu Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.
Zwischen diesen beiden Polen Open Source AI und Closed Source AI gibt es allerdings – wie immer – ein Kontinuum von weiteren Möglichkeiten. Beispielsweise sind LLama, Mistral und Gemma nicht so ohne weiteres den beiden Extremen zuzuordnen, da diese Modelle teilweise offen sind. Solche Modelle werden Open Weights Models genannt:
“As a result, the term “Open Source” has been used to describe models with various levels of openness, many of which should more precisely be described as “open weight” models. Among the Big AI companies, attitudes towards openness vary. Some, like OpenAI or Anthropic, do not release any of their models openly. Others, like Meta, Mistral or Google, release some of their models. These models — for example, Llama, Mistral or Gemma — are typically shared as open weights models” (Tarkowski, A. (2025): Data Governance in Open Source AI. Enabling Responsible and Systemic Access. In Partnership with the Open Source Initiative).
Warum nur werden solche Modelle angeboten? Der Grund kann sein, dass man mit dieser Strategie versucht, dem Regulierungsbestreben z.B. der Europäischen Union entgegenzuwirken. Ich hoffe, dass das nicht funktioniert und Big Tech gezwungen wird, sich an die Spielregeln in der Europäischen Union zu halten. Aktuell sieht es so aus, dass die neue Regierung der USA die Europäische Union auch bei diesem Thema vor sich hertreiben möchte.
Das nächste große Ding in der KI-Entwicklung ist der Einsatz von KI-Agenten (AI Agents). Wie schon in vielen Blogbeiträgen erwähnt, gehen wir auch hier den Weg dafür Open Source zu verwenden. Bei der Suche nach entsprechenden Möglichkeiten bin ich recht schnell auf Langflow gestoßen. Die Vorteile lagen aus meiner Sicht auf der Hand:
(1) Komponenten können per Drag&Drop zusammengestellt werden. (2) Langflow ist Open Source und kann auf unserem eigenen Server installiert werden. Alle Daten bleiben somit auf unserem Server.
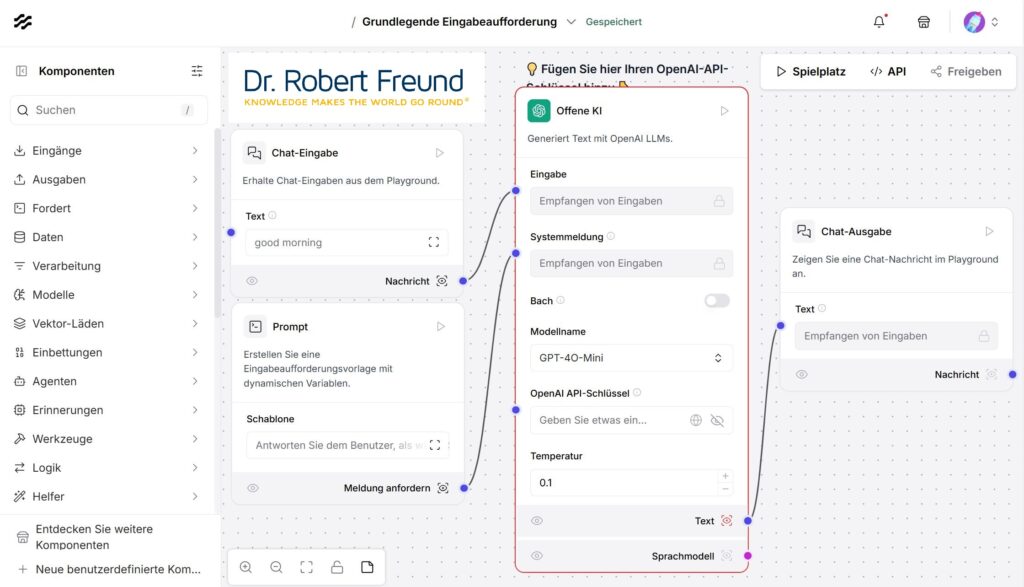
Die Abbildung zeigt einen Screenshot von Langflow – installiert auf unserem Server.
Auf der linken Seite der Abbildung sind viele verschiedene Komponenten zu sehen, die in den grau hinterlegten Bereich hineingezogen werden können. Per Drag&Drop können INPUT-Komponenten und OUTPUT-Format für ein KI-Modell zusammengestellt – konfiguriert – werden. Wie weiterhin zu erkennen, ist standardmäßig OpenAI als KI-Modell hinterlegt. Für die Nutzung wird der entsprechende API-Schlüssel eingegeben.
Mein Anspruch an KI-Agenten ist allerdings, dass ich nicht OpenAI mit ChatGPT nutzen kann, sondern auf unserem Server verfügbare Trainingsdaten von Large Language Models (LLM) oder Small Language Models (SML), die selbst auch Open Source AI sind. Genau diesen Knackpunkt haben wir auch gelöst. Weitere Informationen dazu gibt es in einem der nächsten Blogbeiträge. Siehe in der Zwischenzeit auch
Wenn Sie die bekannten Trainingsmodelle (LLM: Large Language Modells) bei ChatGPT (OpenAI), Gemini (Google) usw. nutzen, werden Sie sich irgendwann als Privatperson, oder auch als Organisation Fragen, was mit ihren eingegebenen Texten (Prompts) oder auch Dateien, Datenbanken usw. bei der Verarbeitung Ihrer Anfragen und Aufgaben passiert.
Antwort: Das weiß keiner so genau, da die KI-Modelle nicht offen und transparent sind.
Um die eigene Souveränität über unsere Daten zu erlangen, haben wir seit einiger Zeit angefangen, uns Stück für Stück von kommerziellen Anwendungen zu lösen. Angefangen haben wir mit NEXTCLOUD, das auf unserem eigenen Server läuft. NEXTCLOUD Hub 9 bietet die Möglichkeiten, die wir alle von Microsoft kennen.
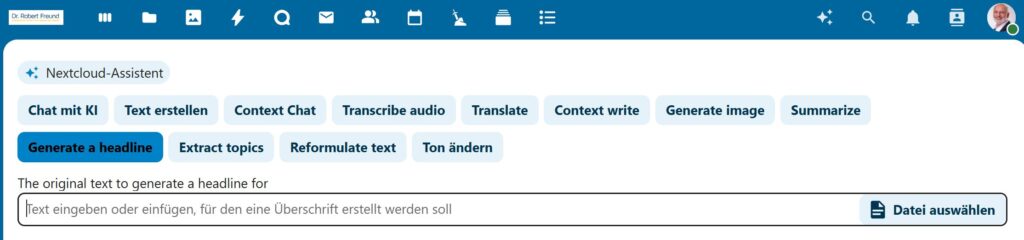
Dazu kommt in der Zwischenzeit auch ein NEXTCLOUD-Assistent, mit dem wir auch KI-Modelle nutzen können, die auf unserem Serverlaufen. Dieses Konzept einer LOCALAI – also einer lokal angewendeten KI – ist deshalb sehr interessant, da wir nicht nur große LLM hinterlegen, sondern auch fast beliebig viele spezialisierte kleinere Trainingsmodelle (SML: Small Language Models) nutzen können. Siehe dazu Free Open Source Software (FOSS): Eigene LocalAI-Instanz mit ersten drei Modellen eingerichtet.
Wie in der Abbildung zu sehen, können wir mit dem NEXTCLOUD Assistenten auch Funktionen nutzen, und auch eigene Dateien hochladen. Dabei werden die Dateien auch mit Hilfe von dem jeweils lokal verknüpften lokalen KI-Modell bearbeitet. Alle Daten bleiben dabei auf unserem Server – ein unschätzbarer Vorteil.
Die Kombination von LOCALAI mit eigenen Daten auf dem eigenen Server macht dieses Konzept gerade für Kleine und Mittlere Unternehmen (KMU) interessant.
In diesem Beitrag geht es mir darum aufzuzeigen, wie Künstliche Intelligenz bei Open Innovation genutzt werden kann. Wie der folgenden Tabelle zu entnehmen ist, kann zwischen der Verbesserung von Open Innovation durch KI (OI-Enhancing AI), einer Ermöglichung von Open Innovation durch KI (OI-Enabling AI) und der Ersetzung von Open Innovation durch KI (OI-Peplacing AI) unterschiedenen werden. Die jeweils genannten Beispiele zeigen konkrete Einsatzfelder.
Description
Examples
OI-Enhancing AI
AI that enhances established forms of open innovation by utilizing the advantages of AI complemented with human involvement
Innovation search Partner search Idea evaluation Resource utilization
OI-Enabling AI
AI that enables new forms of open innovation, based upon AI’s potential to coordinate and/or generate innovation
AI-enabled markets AI-enabled open business models Federated learning
OI-Replacing AI
AI that replaces or significantly reshapes established forms of open innovation
AI ideation Synthetic data Multi-agent systems
Quelle: Holgersson et al. (2024)
Alle drei Möglichkeiten – mit den jeweils genannten Beispielen – können von einem KI-Modell (z.B. ChatGPT oder Gemeni etc.) der eher kommerziell orientierten Anbieter abgedeckt werden. Dieses Vorgehen kann als One Sizes Fits All bezeichnet werden.
Eine andere Vorgehensweise wäre, verschiedene spezialisierte Trainingsmodelle (Large Language Models) für die einzelnen Prozessschritte einzusetzen. Ein wesentlicher Vorteil wäre, dass solche LLM viel kleiner und weniger aufwendig wären. Das ist gerade für Kleine und Mittlere Unternehmen (KMU) von Bedeutung.
Nicht zuletzt kann auch immer mehr leistungsfähige Open Source AI eingesetzt werden. Dabei beziehe ich mich auf die zuletzt veröffentlichte Definition zu Open Source AI. Eine Erkenntnis daraus ist: OpenAI ist kein Open Source AI. Die zuletzt veröffentlichten Modelle wie TEUKEN 7B oder auch Comon Corpus können hier beispielhaft für “wirkliche” Open source AI genannt werden.
Weiterhin speilen in Zukunft AI Agenten – auch Open Source – eine immer wichtigere Rolle.
Innovationen sind für eine Gesellschaft, und hier speziell für marktorientierte Organisationen wichtig, um sich an ein verändertes Umfeld anzupassen (inkrementelle Innovationen), bzw. etwas ganz Neues auf den Markt zu bringen (disruptive Innovationen).
Organisationen können solche Innovationen in einem eher geschlossenen Innovationsprozess (Closed Innovation) oder in einem eher offenen Innovationsprozess (Open Innovation) entwickeln.
Darüber hinaus können die Innovationen von Menschen (People Driven) oder/und von Technologie (Data Driven) getrieben sein. Aktuell geht es in vielen Diskussionen darum, wie Künstliche Intelligenz (AI: Artificial Intelligence) und die damit verbundenen Trainingsdaten (LLM: Large Language Models) im Innovationsprozess genutzt werden können.
Im einfachsten Fall würde sich eine Organisation den Innovationsprozess ansehen, und in jedem Prozessschritt ein Standard-KI-Modell wie ChatGpt, Gemini, Bart usw. nutzen. Die folgende Tabelle stellt das grob für einen einfachen Innovationsprozess nach Rogers (2003) dar:
Opportunity identification and idea generation
Idea evaluation and selection
Concept and solution development
Commercialization launch phase
e.g. identifying user needs, scouting promising technologies, generating ideas;
e.g. idea assessment, evaluation
e.g. prototyping, concept testing
e.g. marketing, sales, pricing
ChatGPT, Gemeni, etc.
ChatGPT, Gemini, etc.
ChatGPT, Gemini, etc.
ChatGPT, Gemini, etc.
Eigene Darstellung
Dieser Ansatz könnte als One Size fits all interpretiert werden: Eine Standard-KI für alle Prozessschritte.
Dafür sprechen verschiedene Vorteile: – Viele Mitarbeiter haben sich schon privat oder auch beruflich mit solchen Standard-KI-Modelle beschäftigt, wodurch eine relativ einfache Kompetenzentwicklung möglich ist. – Die kommerziellen Anbieter treiben AI-Innovationen schnell voran, wodurch es fast “täglich” zu neuen Anwendungsmöglichkeiten kommt. – Kommerzielle Anbieter vernetzen KI-Apps mit ihren anderen Systemen, wodurch es zu verbesserten integrierten Lösungen kommt.
Es gibt allerdings auch erhebliche Nachteile: – Möglicherweise werden auch andere Organisationen/Wettbewerber so einen Ansatz wählen, sodass kaum ein grundlegendes Alleinstellungsmerkmal erzielt werden kann. – Kritisch ist auch heute noch, ob es sich bei den verwendeten Trainingsdaten (Large Language Models) nicht um Urheberrechtsverletzungen handelt. Etliche Klagen sind anhängig. – Weiterhin können die für Innovationen formulierte Prompts und Dateien durchaus auch als Trainingsdaten verwendet werden. – Die LLM sind nicht transparent und für alle zugänglich, also sie sind keine Open Source AI, auch wenn das von den kommerziell betriebenen KI-Modellen immer wieder suggeriert wird. – Organisationen sind anhängig von den Innovationsschritten der kommerziellen Anbieter. – Die Trainingsdatenbanken (Large Language Models) werden immer größer und damit natürlich auch teurer. – Nicht zuletzt ist unklar, wie sich die Kosten für die kommerzielle Nutzung der KI-Apps in Zukunft entwickeln werden – eine gerade für kleine und mittlere Unternehmen (KMU) nicht zu unterschätzende Komponente.
Gerade kleine und mittlere Unternehmen (KMU) sollten die genannten Vorteile und Nachteile abwägen und überlegen, wie sie Künstliche Intelligenz in ihrem Innovationsprozess nutzen wollen.
In unserem Blog werde ich in der nächsten Zeit weitere Möglichkeiten aufzeigen.
Immer mehr Privatpersonen und Organisationen realisieren, dass die populären Trainingsdaten (LLM: Large Language Models) für ChatGPT von OpanAI, oder auch Gemini von Google usw., so ihre Tücken haben können, wenn es beispielsweise im andere oder um die eigenen Urheberrechte geht. In diesem Punkt unterscheiden wir uns in Europa durchaus von den US-amerikanischen und chinesischen Ansätzen. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich. Darüber hinaus liegen die Daten der bekannten (closed source) LLMs zu einem überwiegenden Teil in englischer oder chinesischer Sprache vor.
“Multilingual, open source models for Europe – instruction-tuned and trained in all 24 EU languages…. Training on >50% non English Data. (…) This led to the creation of a custom multilingual tokenizer” (ebd.).
Neben der freien Verfügbarkeit (Open Source AI) (via Hugging Face) ist somit ein großer Pluspunkt, dass eine große Menge an Daten, nicht englischsprachig sind. Das unterscheidet dieses Large Language Model (LLM) sehr deutlich von den vielen englisch oder chinesisch dominierten (Closed Source) Large Language Models.
Insgesamt halte ich das alles für eine tolle Entwicklung, die ich in der Geschwindigkeit nicht erwartet hatte!
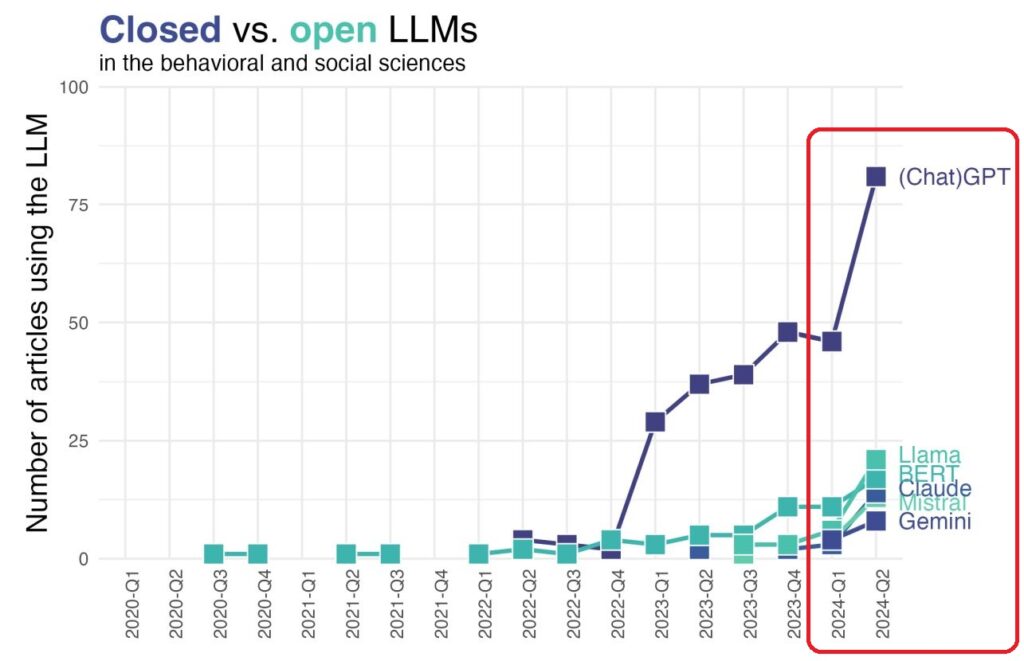
Usage of large language models (LLMs) in behavioral and social sciences research (Wulff/Hussain/Mata 2024). Die Hervorhebung in Rot ist von mir (Robert Freund) ergänzt worden.
Natürlich verwenden immer mehr Wissenschaftler Künstlichen Intelligenz in ihrer Arbeit. Wie die Grafik zeigt, wird ChatGPT beispielsweise in den Verhaltens- und Sozialwissenschaften sehr stark genutzt. ChatGPT ist allerdings von OpenAI, dessen Large Language Model (LLM) als eher geschlossenes System (Closed LLM) bezeichnet werden kann, da das zugrundeliegende Datenmodell nicht transparent ist. Andere LLM – wie z.B. LLama – sind eher offen LLM (Open LLM), die gerade für Forschung und Wissenschaft geeigneter erscheinen.
“Academic research should prefer open LLMs because they offer several practical and ethical advantages that are essential for scientific progress.
First, open models provide the transparency necessary for thorough scrutiny, allowing researchers to understand better the tools they are using and ensuring accountability.
Second, this transparency, combined with the adaptability of open models, facilitates innovation by enabling researchers to customize models to meet specific needs and explore new applications (Wulff & Mata, 2024).
Third, open LLMs support reproducibility, a cornerstone of scientific research, by allowing other researchers to replicate and build upon existing work.
Finally, the ethical implications of AI usage are better managed with open models, as they enable greater scrutiny of AI decisions, arguably reduce the risks of deploying biased or unethical systems, and avoid giving away data to further train closed, proprietary models.”
Ich frage mich an dieser Stelle, ob solche Hinweise nicht auch für die Nutzung von Künstlicher Intelligenz in Unternehmen gelten sollten.
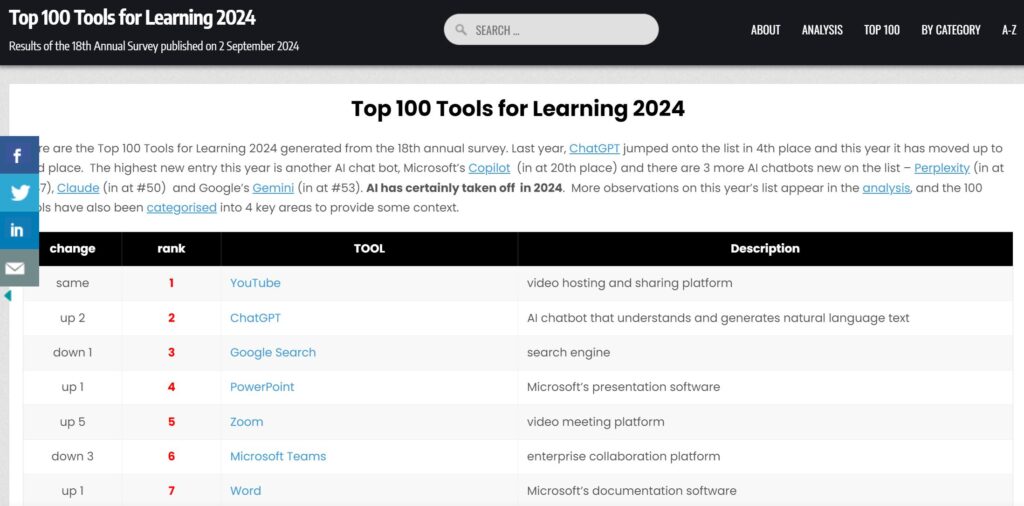
Es ist nicht verwunderlich, dass immer mehr KI-Anwendungen in der Liste der 100 Tools for Learning auftauchen. ChatGPT ist vom 4. auf den 2. Platz vorgerückt und weitere KI-Copilots tauchen in der Liste auf, bzw. rücken auch in den Platzierung vor. Es sieht so aus, als ob immer mehr KI-Anwendungen für Lernprozesse genutzt werden.
Es ist daher für viele an der Zeit, sich mit den Möglichkeiten und Beschränkungen von KI-Anwendungen bei Lernprozessen zu befassen. Am besten geht das in Unternehmen natürlich im Prozess der Arbeit: Kompetenzentwicklung im Prozess der Arbeit.
OpenAI ist mit ChatGPT etc. inzwischen weltweit erfolgreich am Markt. Angefangen hat das damalige Start-up mit der Idee, Künstliche Intelligenz (AI) als Anwendung offen, und damit frei verfügbar und transparent anzubieten. – ganz im Sinne der Open Source Idee.
Durch den Einstieg von Microsoft ist der Name OpenAI zwar geblieben, doch sind die Angebote in der Zwischenzeit eher als geschlossenes, intransparentes System einzuordnen, mit dem die Inhaber (Shareholder) exorbitante Gewinne erzielen möchten.
Dieser Problematik hat sich eine Personengruppe angenommen, und eine erste Definition für Open Source AI erarbeitet, anhand der die aktuellen KI-Apps bewertet werden können: In dem Artikel MIT Technology Review (2024): We finally have a definition for open-source AI (Massachusetts Institut of Technology, 22.08.224) findet sich dazu folgendes:
“According to the group, an open-source AI system can be used for any purpose without securing permission, and researchers should be able to inspect its components and study how the system works.
It should also be possible to modify the system for any purpose—including to change its output—and to share it with others to use, with or without modifications, for any purpose. In addition, the standard attempts to define a level of transparency for a given model’s training data, source code, and weights.”
Die Intransparenz der Trainingsdaten bei den eher geschlossenen KI-Systemen von OpenAI, Meta und Google führt aktuell dazu, dass sich diese Unternehmen mit sehr vielen Klagen und Rechtstreitigkeiten auseinandersetzen müssen.
Die Open Source Initiative (OSI) plant, eine Art Mechanismus zu entwickeln, der bei den jeweiligen KI-Anwendungen anzeigt, ob es sich wirklich um Open Source KI-Anwendungen handelt