Über die Open Source AI-Modelle der Olmo2-Familie habe ich schon einmal in diesem Blogbeitrag geschrieben. Grundsätzlich soll mit diesen Modellen die Forschung an Sprachmodellen unterstützt werden. Anfang November hat Ai2 nun bekannt gegeben, dass mit OlmoEarth eine weitere Modell-Familie als Foundation Models (Wikipedia) zur Verfügung steht.
„OlmoEarth is a family of open foundation models built to make Earth AI practical, scalable, and performant for real-world applications. Pretrained on large volumes of multimodal Earth observation data“ (Source: Website).
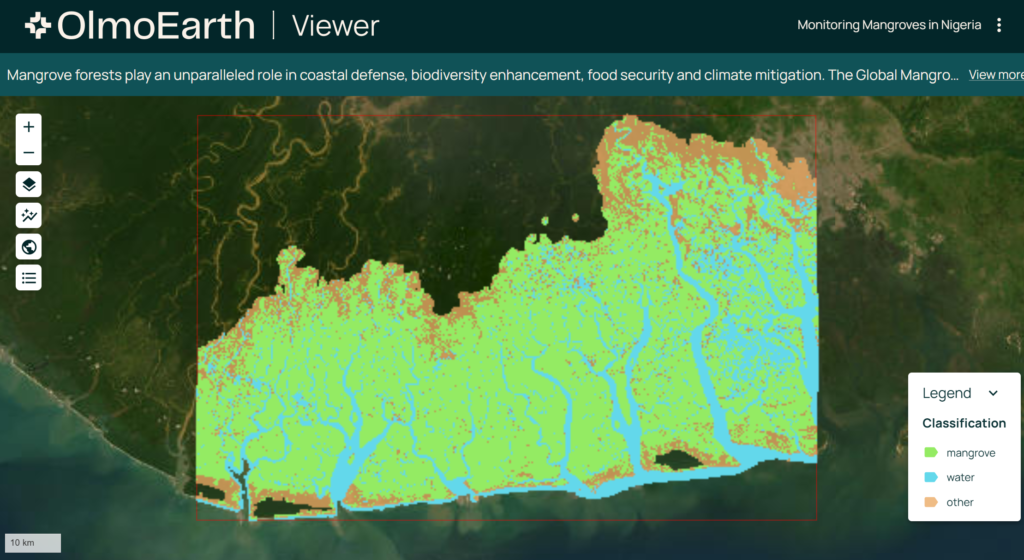
Es handelt sich also um eine offene, trainierte Modell-Familie, die zur Lösung realer Probleme (real world problems) beitragen sollen. Hier ein Beispiel von der Nutzung der Daten für eine Fragestellung in Nigeria:
Es gibt vier unterschiedliche Modelle. Interessant dabei ist, dass es auch kleine Modelle (Nano und Tiny) gibt, die kostengünstig sind, und schnell genutzt werden können:
Wenn es um Künstliche Intelligenz geht, kommt auch immer öfter der Hinweis auf, dass Emotionale Intelligenz immer wichtiger wird. In dem Blogbeitrag AI City und Emotionale Intelligenz wird beispielsweise auf den Zusammenhang mit AI Citys verwiesen:
“For a smart city, having only “IQ” (intelligence quotient) is not enough; “EQ” (emotional quotient) is equally essential. (…) the emotions of citizen communities …“
Hier wird also vorgeschlagen, neben dem Intelligenz-Quotienten (IQ) noch einen Emotionalen Quotienten (EQ) bei der Betrachtung zu berücksichtigen.
Doch was verstehen wir unter „Emotionale Intelligenz“?
Ich beziehe mich hier auf eine Beschreibung von Salovay und Mayer, und bewusst nicht auf den populären Ansatz von Goleman:
“Emotional intelligence is a type of social intelligence that involves the ability to monitor one’s own and others’ emotions to discriminate among them, and to use the information to guide one’s thinking and actions (Salovey & Mayer 1990)”, cited in Mayer/Salovay 1993, p. 433).
Die Autoren sehen also Emotionale Intelligenz als Teil einer Sozialen Intelligenz. Spannend ist weiterhin, dass Mayer und Salovay ganz bewusst einen Bezug zur Multiplen Intelligenzen Theorie von Howard Gardner herstellen. Siehe Emotionale Intelligenz: Ursprung und der Bezug zu Multiplen Intelligenzen.
Betrachten wir nun Menschen und AI Agenten im Zusammenspiel, so muss geklärt werden, woran AI Agenten (bisher) bei Entscheidungen scheitern. Dazu habe ich folgenden Text gefunden:
“AI agents don’t fail because they’re weak at logic or memory. They fail because they’re missing the “L3” regions — the emotional, contextual, and motivational layers that guide human decisions every second” (Bornet 2025 via LinkedIn).
Auch Daniel Goleman, der den Begriff „Emotionale Intelligenz“ populär gemacht hat, beschreibt den Zusammenhang von Emotionaler Intelligenz und Künstlicher Intelligenz am Arbeitsplatz, und weist auf die erforderliche Anpassungsfähigkeit (Adaptability) hin:
„Adaptability: This may be the key Ei competence in becoming part of an AI workplace. Along with emotional balance, our adaptability lets us adjust to any massive transformation. The AI future will be different from the present in ways we can’t know in advance“ (EI in the Age of AI, Goleman via LinkedIn, 30.10.2025).
Bei Innovationen sollten wir uns zunächst einmal klar machen, was im Unternehmenskontext darunter zu verstehen ist. Das Oslo Manual schlägt vor, Innovation wie folgt zu interpretieren:
„(…) a new or improved product or process (or combination thereof) that differs significantly from the unit’s previous products or processes and that has been made available to potential users (product) or brought into use by the unit (process)” (Oslo Manual 2018).
Dass Innovation u.a. eine Art Neu-Kombination von Existierendem bedeutet, ist vielen oft nicht so klar (combination thereof). Neue Ideen – und später Innovationen – entstehen oft aus vorhandenen Konzepten. oder Daten.
An dieser Stelle kommen nun die Möglichkeiten der Künstlichen Intelligenz (GenAI oder auch AI Agenten) ins Spiel. Mit KI ist es möglich, fast unendlich viele Neu-Kombinationen zu entwickeln, zu prüfen und umzusetzen. Das können Unternehmen nutzen, um ihre Innovationsprozesse neu zu gestalten, oder auch jeder Einzelne für seine eigenen Neu-Kombinationen im Sinne von Open User Innovation nutzen. Siehe dazu Von Democratizing Innovation zu Free Innovation.
Entscheidend ist für mich, welche KI-Modelle dabei genutzt werden. Sind es die nicht-transparenten Modelle der Tech-Unternehmen, die manchmal sogar die Rechte von einzelnen Personen, Unternehmen oder ganzer Gesellschaften ignorieren, oder nutzen wir KI-Modelle, die frei verfügbar, transparent und für alle nutzbar sind (Open Source AI)?
Es ist deutlich zu erkennen, dass Künstliche Intelligenz in seinen verschiedenen Formen (GenAI, AI Agenten usw.) Berufsbilder, Lernen, Wissens- und Kompetenzentwicklung beeinflusst, bzw. in Zukunft noch stärker beeinflussen wird. Siehe dazu beispielsweise WEF Jobs Report 2025.
Auch Strukturen im Bildungsbereich müssen sich daher fragen, welche Berechtigung sie noch in Zukunft haben werden, da sich der aktuelle Bildungssektor in fast allen Bereichen noch stark an den Anforderungen der Industriegesellschaft orientiert. Wenn es beispielsweise um Schulen geht, hat sich seit mehr als 100 Jahren nicht viel geändert. Siehe dazu Stundenplan von 1906/1907: Geändert hat sich bis heute (fast) nichts. Dazu passt folgendes Zitat:
„Every time I pass a jailhouse or a school, I feel sorry for the people inside.“ — Jimmy Breslin, Columnist, New York Post (Quelle)
Wohin sollen sich die Bildungsstrukturen – hier speziell Schulen – entwickeln?
(1) Wir können die Technologischen Möglichkeiten von Künstlicher Intelligenz in den Mittelpunkt stellen, und Menschen als nützliches Anhängsel von KI-Agenten verstehen. Dabei werden Menschen auf die KI-Technologie trainiert,, weiter)gebildet, geschult.
(2) Wir können alternativ Menschen und ihr soziales Zusammenleben in den Mittelpunkt stellen, bei dem Künstliche Intelligenz einen wertvollen Beitrag liefern kann. Ganz im Sinne einer Society 5.0.
Aktuell dominiert fast ausschließlich die Nummer (1) der genannten Möglichkeiten, was dazu führen kann, dass der Bildungsbereich Menschen so trainiert, dass sie zu den von Tech-Giganten entwickelten Technologien passen.
Möglicherweise hilft es in der Diskussion, wenn man den Ursprung des Wortes „Schule“ betrachtet. Der Begriff geht auf das griechische Wort „Skholè“ zurück, was ursprünglich „Müßiggang“, „Muße“, bedeutet und später zu „Studium“ und „Vorlesung“ wurde (Quelle: Wikipedia).
Bei Forschungen zur Künstlichen Intelligenz sind Autoren genau darauf eingegangen, weil sie vermuten, dass gerade diese ursprüngliche Perspektive besser zu den aktuellen Entwicklung passen kann:
„We find this etymology deeply revealing because it undercovers a profound truth about education´s original purpose: it wasn´t about preparing workers for jobs, but about providing space for thoughtful reflection and exploration of life´s fundamental questions. What inspires us about the ancient´s Greek approach is how they saw education as a means to help people find their purpose and develop their full potential as human beings“ (Bornet et al. 2025).
Auch der Jobs Reports 2025 des WEF zeigt auf, dass bis 2030 wohl 172 Millionen neue Jobs entstehen, und 92 Millionen wegfallen werden. Es geht dabei nicht immer um komplette Jobs, sondern auch um Teilbereiche oder Tätigkeitsportfolios, die immer mehr von AI Agenten übernommen werden (können).
Alles was mit Logik und Speicherung zu tun hat, ist eher die Stärke von Künstlicher Intelligenz, den Workflows, bzw. den AI Agenten. Doch in welchen Bereichen versagen AI Agenten noch? Dazu habe ich den folgenden Text gefunden:
„AI agents don’t fail because they’re weak at logic or memory. They fail because they’re missing the “L3” regions — the emotional, contextual, and motivational layers that guide human decisions every second“ (Bornet 2025 via LinkedIn).
Dabei bezieht sich Bornet auf eine Veröffentlichung von Bang Liu et al. (2025:19-20), in dem die Autoren drei Hirnregionen in Bezug auf AI (Artificial Intelligence) untersuchten. L1: Well developed; L2: Partially developed; L3: Underexplored.
Das Ergebnis ist also, dass AI Agenten in den Ebenen Emotionen, Kontext und Motivation unterentwickelt sind (L3), wenn es um menschliche Entscheidungen geht.
Erkenntnis (Cognition) entsteht dabei nicht nur in einem Bereich im Gehirn, sondern durch das Zusammenspiel vieler unterschiedlich vernetzter Areale. Bei komplexen Problemlösungsprozesse (CPS: Complex Problem Solving) geht es verstärkt um Emotionen, Kontext und Motivation.
Im Idealfall könnten Menschen an diesen Stellen einen Mehrwert für eine qualitativ gute Problemlösung (Erkenntnis) einbringen. Es stellt sich dabei allerdings auch die Frage, wie stark sich Menschen an die Möglichkeiten einer Künstlichen Intelligenz (AI Agenten) anpassen sollen.
Zusätzlich können die in dem sehr ausführlichen wissenschaftlichen Paper von Bang Liu et al. (2025) erwähnten Zusammenhänge Hinweise geben, wie die Zusammenarbeit – das Zusammenspiel – zwischen Menschen und AI Agenten organisiert, ja ermöglicht werden kann.
In allen Projekten werden mehr oder weniger oft digitale Tools, bzw. komplette Kollaborationsplattformen eingesetzt. Hinzu kommen jetzt immer stärker die Möglichkeiten der Künstlicher Intelligenz im Projektmanagement (GenAI, KI-Agenten usw.).
Projektverantwortliche stehen dabei vor der Frage, ob sie den KI-Angeboten der großen Tech-Konzerne vertrauen wollen – viele machen das. Immerhin ist es bequem, geht schnell und es gibt auch gute Ergebnisse. Warum sollte man das hinterfragen? Möglicherweise gibt es Gründe.
Es ist schon erstaunlich zu sehen, wie aktuell Mitarbeiter ChatGPT, Gemini usw. mit personenbezogenen Daten (Personalwesen) oder auch unternehmensspezifische Daten (Expertise aus Datenbanken) füttern, um schnelle Ergebnisse zu erzielen – alles ohne zu fragen: Was passiert mit den Daten eigentlich? Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Es stellt sich zwangsläufig die Frage, wie man diesen Umgang mit den eigenen Daten und das dazugehörende Handeln bewertet. An dieser Stelle kommt der Begriff Ethik ins Spiel, denn Ethik befasst sich mit der „Bewertung menschlichen Handelns“ (Quelle: Wikipedia). Dazu passt in Verbindung zu KI in Projekten folgende Textpassage:
„In vielen Projektorganisationen wird derzeit intensiv darüber diskutiert, welche Kompetenzen Führungskräfte in einer zunehmend digitalisierten und KI-gestützten Welt benötigen. Technisches Wissen bleibt wichtig – doch ebenso entscheidend wird die Fähigkeit, in komplexen, oft widersprüchlichen Entscheidungssituationen eine ethisch fundierte Haltung einzunehmen. Ethische Kompetenz zeigt sich nicht nur in der Einhaltung von Regeln, sondern vor allem in der Art, wie Projektleitende mit Unsicherheit, Zielkonflikten und Verantwortung umgehen“ (Bühler, A. 2025, in Projektmanagement Aktuell 4/2025).
Unsere Idee ist daher, eine immer stärkere eigene Digitale Souveränität – auch bei KI-Modellen. Nextcloud, LocalAI, Ollama und Langflow auf unseren Servern ermöglichen es uns, geeigneter KI-Modelle zu nutzen, wobei alle generierten Daten auf unseren Servern bleiben. Die verschiedenen KI-Modelle können farbig im Sinne einer Ethical AI bewertet werden::
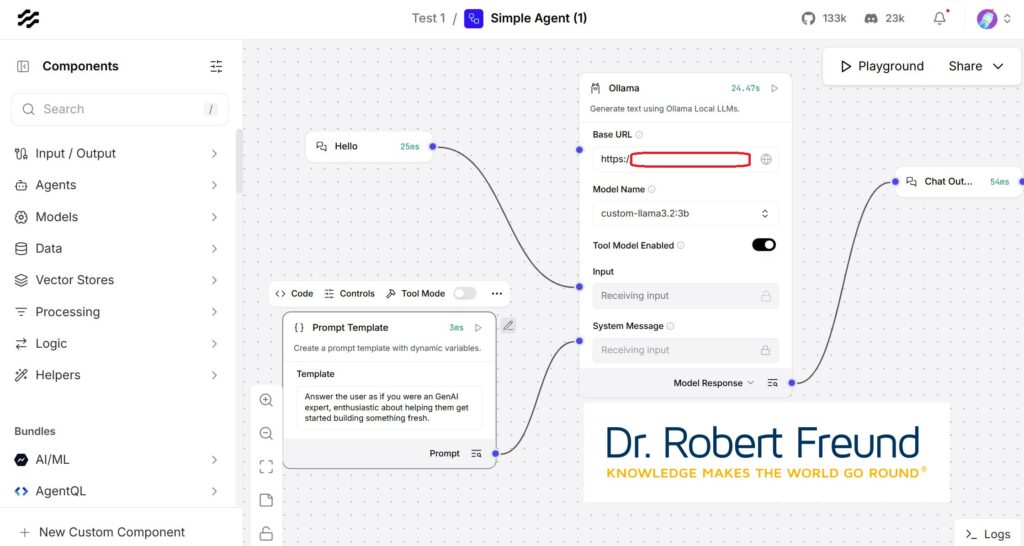
Eigener Screenshot vom Langflow-Arbeitsbereich, inkl. der Navigation auf der linken Seite
Langflow haben wir als Open Source Anwendung auf unseren Servern installiert. Mit Langflow ist es möglich, Flows und Agenten zu erstellen – und zwar einfach mit Drag&Drop. Na ja, auch wenn es eine gute Dokumentation und viele Videos zu Langflow gibt, steckt der „Teufel wie immer im Detail“.
Wenn man mit Langflow startet ist es erst einmal gut, die Beispiele aus den Dokumentationen nachzuvollziehen. Ich habe also zunächst damit begonnen, einen Flow zu erstellen. Der Flow unterscheidet sich von Agenten, auf die ich in den nächsten Wochen ausführlicher eingehen werde.
Wie in der Abbildung zu sehen ist, gibt es einen Inputbereich, das Large Language Model (LLM) oder auch ein kleineres Modell, ein Small Language Model (SLM). Standardmäßig sind die Beispiele von Langflow darauf ausgerichtet, dass man OpenAI mit einem entsprechenden API-Key verwendet. Den haben wir zu Vergleichszwecken zwar, doch ist es unser Ziel, alles mit Open Source abzubilden – und OpenAI mit ChatGPT (und andere) sind eben kein Open Source AI.
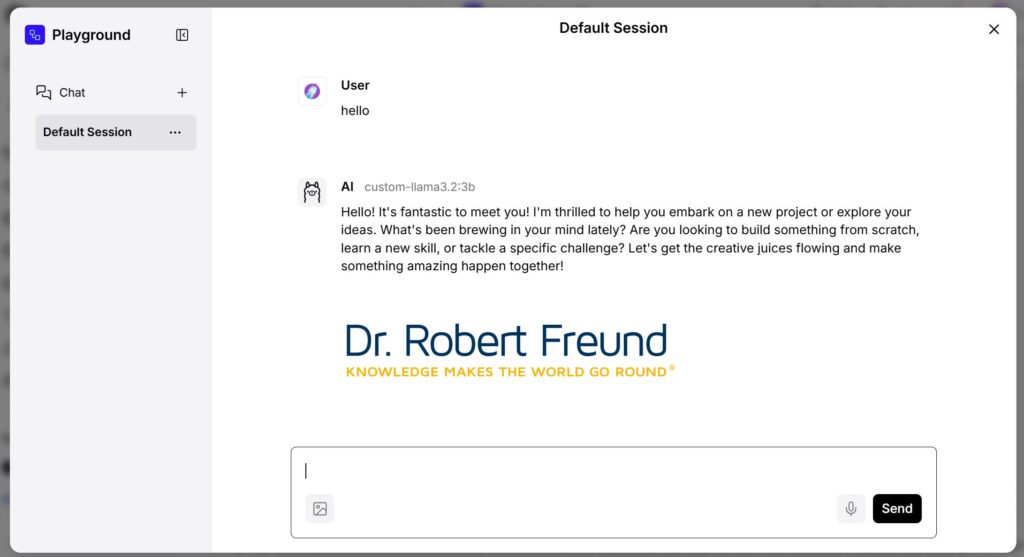
Um das zu erreichen, haben wir Ollama auf unseren Servern installiert. In der Abbildung oben ist das entsprechende Feld im Arbeitsbereich zu sehe,n. Meine lokale Adresse für die in Ollama hinterlegten Modelle ist rot umrandet unkenntlich gemacht. Unter „Model Name“ können wir verschiedene Modelle auswählen. In dem Beispiel ist es custom-llama.3.2:3B. Sobald Input, Modell und Output verbunden sind, kann im Playground (Botton oben rechts) geprüft werden, ob alles funktioniert. Das Ergebnis sieht so aus:
Screenshot vom Playground: Ergebnis eines einfachen Flows in Langflow
Es kam mir jetzt nicht darauf an, komplizierte oder komplexe Fragen zu klären, sondern überhaupt zu testen, ob der einfache Flow funktioniert. Siehe da: Es hat geklappt!
Alle Anwendungen (Ollama und Langflow) sind Open Source und auf unseren Servern installiert. Alle Daten bleiben auf unseren Servern. Wieder ein Schritt auf dem Weg zur Digitalen Souveränität.
Weltweit werden KI-Giga-Factories gebaut, um den erforderlichen Rechenkapazitäten der großen Tech-Konzerne gerecht zu werden. Europa fällt auch hier immer weiter zurück, wodurch eine zusätzliche digitale Abhängigkeit entsteht.
Prof. Lippert vom Kernforschungszentrum hat das so ausgedrückt: „“Unser geistiges Eigentum geht in andere Länder“ (MDR vom 05.09.2025). Teilweise wird prognostiziert, dass KI-Rechenzentren bis 2030 so viel Energie benötigen, wie ganz Japan.
Es stellt sich daher die Frage, ob das langfristig der richtige Weg ist. Eine Antwort liefert möglicherweise der Energieverbrauch eines menschlichen Gehirns:
„Unser Gehirn benötigt für hochkomplexe Informationsübertragungen und -verarbeitungen weniger Energie als eine 30-Watt-Glühbirne“ (Prof. Dr. Amunts).
Mit so einer geringen Energiemenge leistet unser menschliches Gehirn erstaunliches. Es wundert daher nicht, dass die Entwicklung immer größerer Modelle (Large Language Models) infrage gestellt wird.
Forscher sind aktuell auf der Suche nach Modellen, die ganz anders aufgebaut sind und nur einen Bruchteil der aktuell benötigten Energie verbrauchen. Gerade in China gibt es dazu schon deutliche Entwicklungen. Auch in Deutschland befassen sich Forscher mit dem Thema neuroinspirierte Technologien.
In den letzten Jahren wird immer deutlicher, dass Künstliche Intelligenz unser wirtschaftliches und gesellschaftliches Leben stark durchdringen wird. Dabei scheint es so zu sein, dass die Künstliche Intelligenz der Menschlichen Intelligenz weit überlegen ist. Beispielsweise kann Künstliche Intelligenz (GenAI) äußerst kreativ sein, was in vielfältiger Weise in erstellten Bildern oder Videos zum Ausdruck kommt. In so einem Zusammenhang behandeln wir Künstliche Intelligenz (AI: Artificial Intelligence) wie Kreative und im Gegensatz dazu Menschen eher wie Roboter. Dazu habe ich folgenden Text gefunden:
„We are treating humans as robots and ai as creatives. it is time to flip the equation“ (David de Cremer in Bornet et al. 2025).
David de Cremer ist der Meinung, dass wir die erwähnte „Gleichung“ umstellen sollten. Dem kann ich nur zustimmen, denn das aktuell von den Tech-Giganten vertretene Primat der Technik über einzelne Personen und sogar ganzen Gesellschaften sollte wieder auf ein für alle Beteiligten gesundes Maß reduziert werden. Damit meine ich, dass die neuen technologischen Möglichkeiten einer Künstlichen Intelligenz mit den Zielen von Menschen/Gesellschaften und den möglichen organisatorischen und sozialen Auswirkungen ausbalanciert sein sollten.
AI2 ist eine Non-Profit Organisation, die Künstliche Intelligenz für die vielfältigen gesellschaftlichen Herausforderungen entwickelt. Das 2014 in Seattle gegründete Institut stellt dabei auch verschiedene Open Source KI-Modelle zur Verfügung – u.a. auch OLMo2.
„OLMo 2 is a family of fully-open language models, developed start-to-finish with open and accessible training data, open-source training code, reproducible training recipes, transparent evaluations, intermediate checkpoints, and more“ (Quelle).
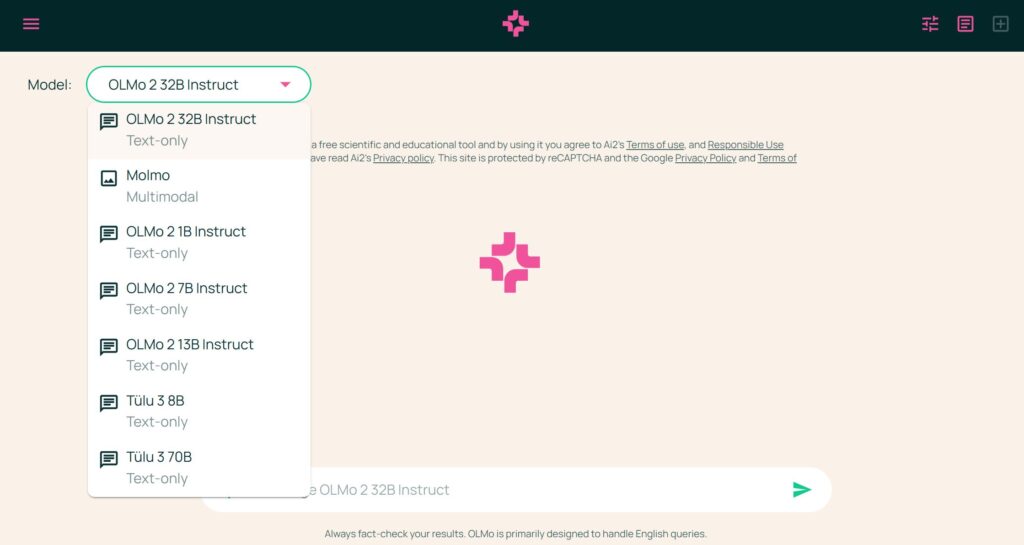
Wenn man die von AI2 veröffentlichten KI-Modelle einmal testen möchte, kann man das nun in einem dafür eingerichteten Playground machen. Wie in der Abbildung zu erkennen, können Sie einzelne Modelle auswählen, und mit einem Prompt testen. Der direkte Vergleich der Ergebnisse zeigt Ihnen, wie sich die Modelle voneinander unterscheiden.