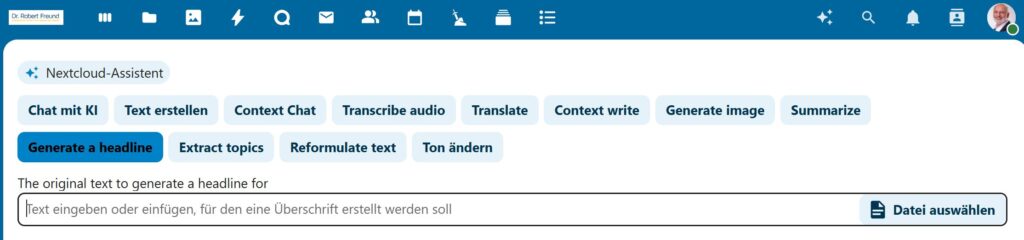
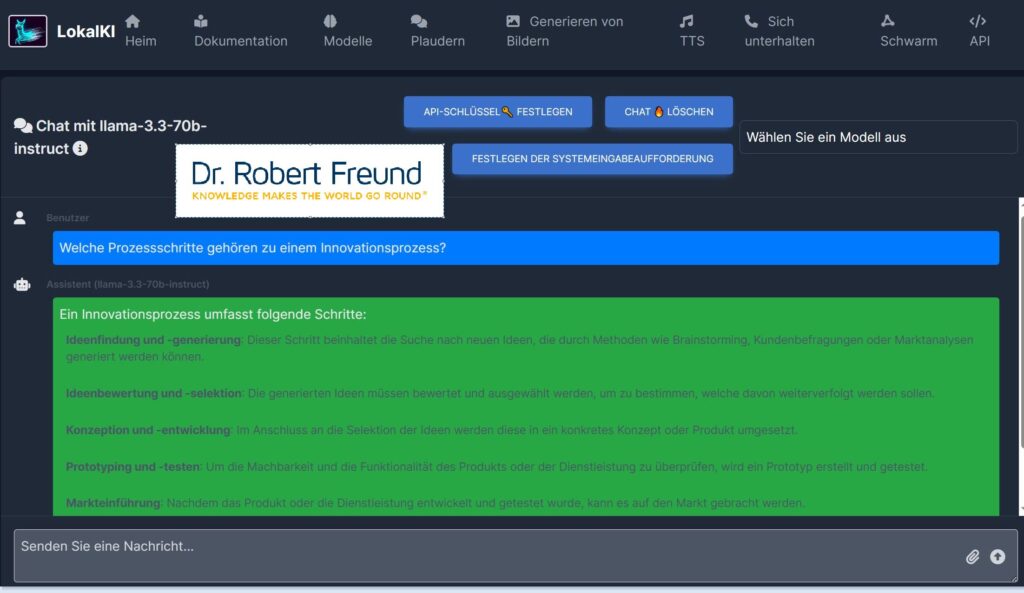
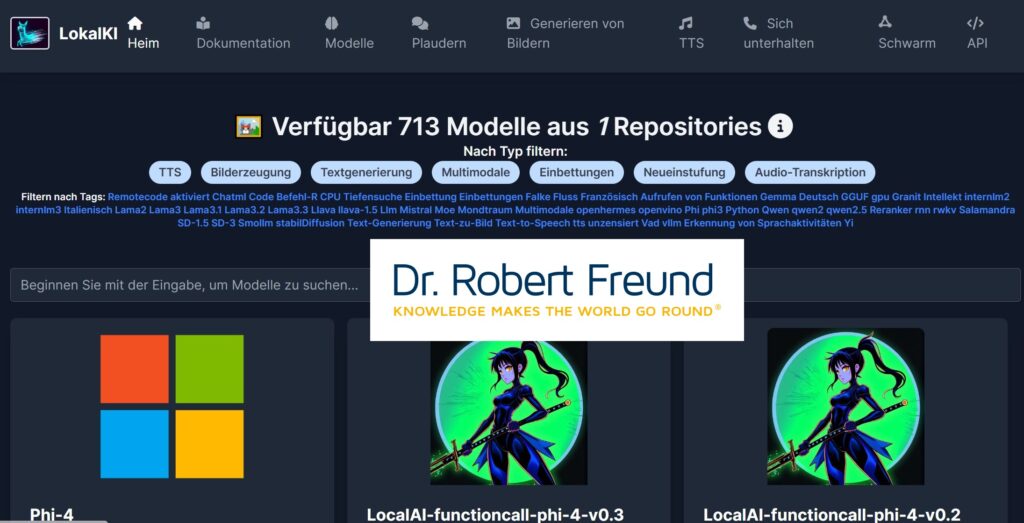
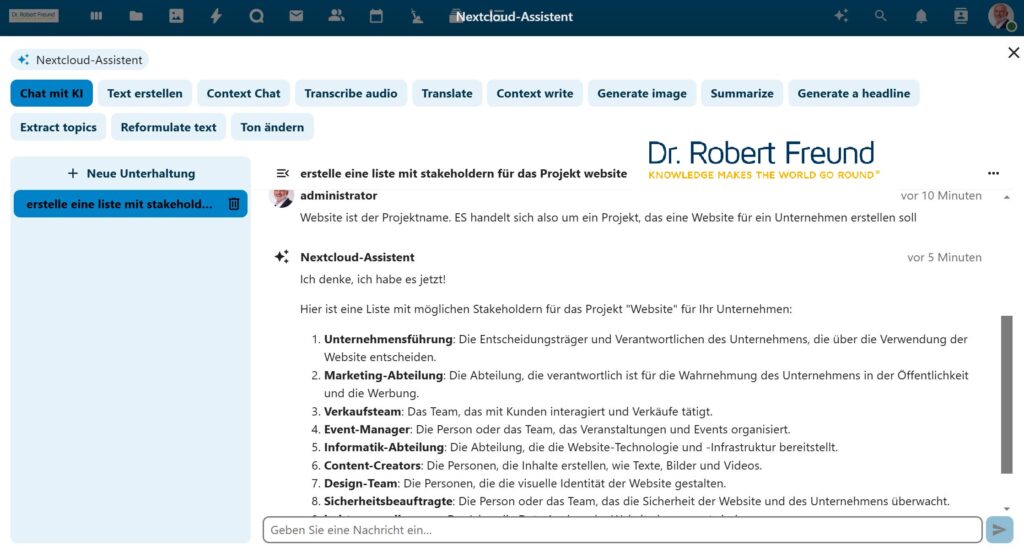
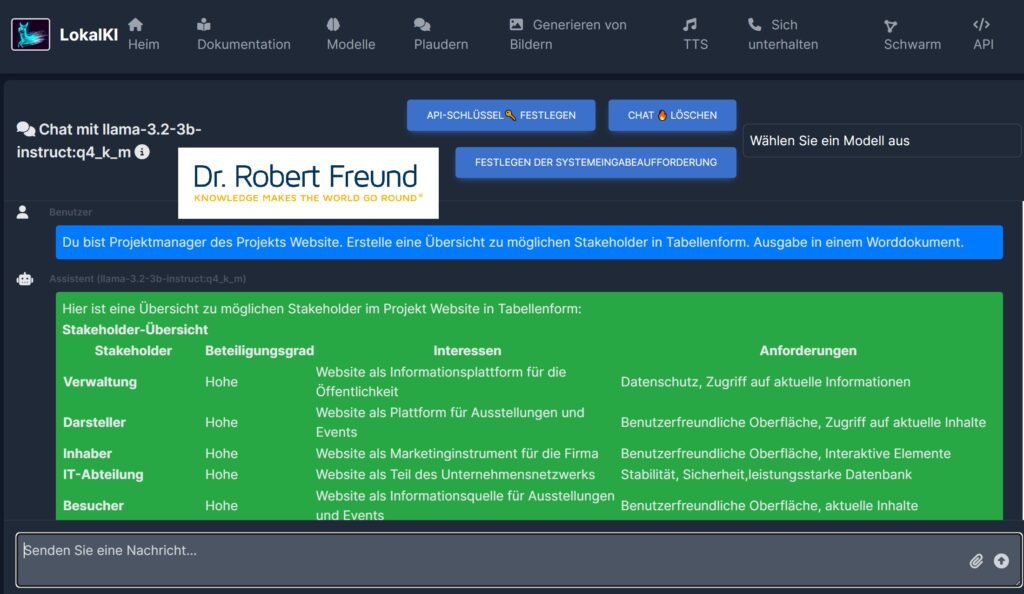
Gerade im Agilen Projektmanagement werden Anforderungen häufig für Persona formuliert. Diese sind nach dem IREB (International Requirements Engineering Board) fiktive Charaktere, mit deren Hilfe Werte für die User geschaffen werden sollen. Dieses Vorgehen erinnert an eine Art Segmentierung aus dem traditionellen Marketing.
Mass Customization auf der anderen Seite ist eine hybride Wettbewerbsstrategie, die individuelle Produkte und Dienstleistungen für jeden Abnehmer – also massenhaft – anbietet, bei Preisen, die denen der massenhaft produzierten Standardprodukten ähneln. Dabei ist der Konfigurator ein wichtiges Element, das passende Produkt in einem Fixed Solution Space (Definierter Lösungsraum) zu erstellen. Die dahinterliegende Idee eines “Market of One” passt nicht so recht mit der Persona-Idee zusammen. Dazu habe ich folgendes gefunden:
“In many ways, a persona is the opposite of mass customization. It’s more traditional marketing thinking about how to deal with a larger number of segments. A “persona of one” is turning the persona idea to its opposite” Piller, Frank T. and Euchner, James, Mass Customization in the Age of AI (June 07, 2024). Research-Technology Management, volume 67, issue 4, 2024 [10.1080/08956308.2024.2350919], Available at SSRN: https://ssrn.com/abstract=4887846.
In Zeiten von Künstlicher Intelligenz wird es immer mehr Möglichkeiten geben, Produkte und Dienstleistungen massenhaft zu individualisieren und zu personalisieren. Ob die Verwendung von Persona in solchen eher agil durchzuführenden Projekten dann noch angemessen ist, scheint fraglich zu sein. Siehe dazu auch
Society 5.0 und Mass Customization
Wir sind dabei: 20 Jahre MCP-CE vom 24.-27.09.2024