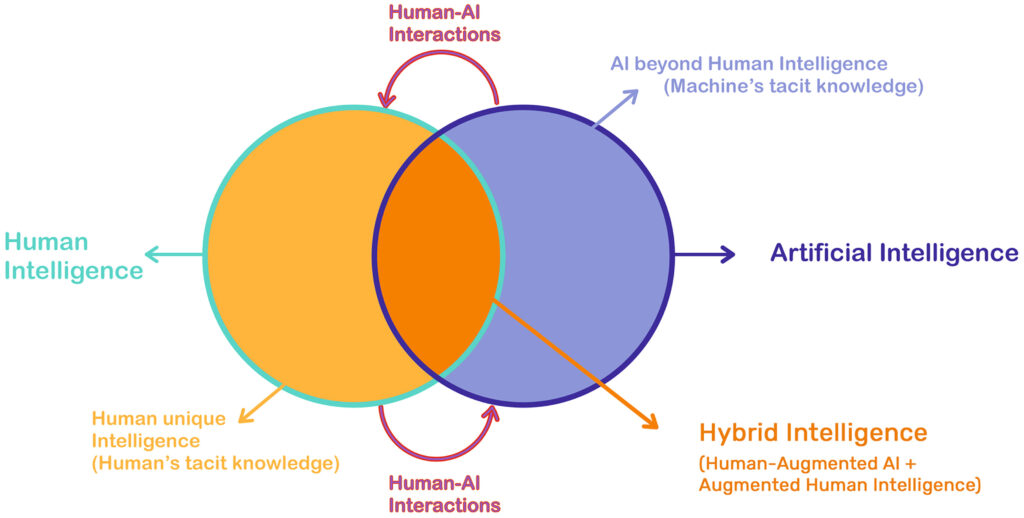
Wenn es um die Beschreibung des Umfeldes geht, verwenden wir oft den Begriff “Ungewissheit”. Dabei wird allerdings nicht immer erkannt, dass “Ungewissheit” zwei Dimensionen enthält, die ganz unterschiedlich gehandhabt werden müssen. Einerseits sind es die “Known Unknowns“, die mit den bekannten Managementansätzen (Risikomanagement) angegangen werden können. Eine weitaus wichtigere Dimension stellen allerdings die “Unknown Unknowns” dar. Dazu habe ich folgenden Text gefunden:
“Wichtig ist beim Blick auf Ungewissheit die Unterscheidung zwischen „Known Unknowns“ und „Unknown Unknowns“. Ersteres bezieht sich auf die Bearbeitung von Risiken und das Risikomanagement. Ziel ist, nicht vollständig vorhersehbare und kontrollierbare Ereignisse gleichwohl weitmöglichst zu beschreiben und die Wahrscheinlichkeit ihres Eintretens zu berechnen. Auf dieser Grundlage erscheint es dann auch möglich, den Umgang mit Risiken zu planen und ein entsprechendes Risikomanagement zu entwickeln. Demgegenüber besteht bei „Unknown Unknowns“ Ungewissheit sowohl über die konkreten Erscheinungsformen als auch die jeweils situativen Bedingungen (Zeit, Ort, Umfang) ihres Auftretens. Risiken und das Risikomanagement lassen sich somit weitgehend dem klassischen Management mit Planung und Kontrolle zuordnen, wohingegen die „Unknown Unknowns“ die eigentliche Ungewissheit benennen und ein weitgehend „blinder Fleck“ im Projektmanagement sowie auch Management insgesamt sind” (Boehle et al 2018, in projektmanagementaktuell 1/2018).
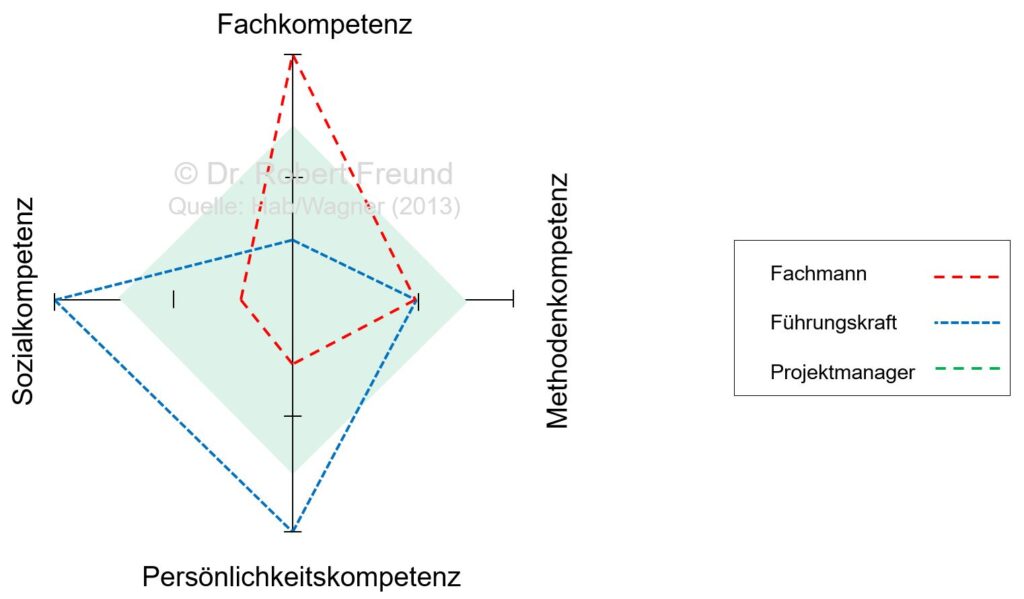
Es wird in Zukunft immer entscheidender sein, wie Management mit beiden Dimensionen umgeht. Aktuell liegt der Fokus auf den “Known Unknowns”, für das eher klassisches Management und auf Technologien, wie z.B. auch Künstliche Intelligenz, angewendet wird – dabei werden die “Unknown Unknowns” häufig vernachlässigt. Gerade bei der Bewältigung von “Unknown Unknowns” kommt dem Menschen eine bedeutende Rolle zu, da der Mensch in der Lage ist diese Form der Ungewissheit zu bewältigen. Siehe dazu auch Über den Umgang mit Ungewissheit und Kompetenzmanagement.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.