Wir (Jutta und ich) sind Fans der EXPO, da die Weltausstellungen die vielen positiven Seiten der Welt zeigen. Die Länder-Pavilions zeigen neue, innovative und interessante Entwicklungen, aus allen Regionen der Welt.
Wir haben schon verschiedene Weltausstellungen besucht, u.a. natürlich die Weltausstellungen in Hannover, in Mailand und Dubai. In Dubai waren wir sogar über Silvester, was noch einmal einen besonderen Kick ergab.
Jetzt also die Expo 2025 in Osaka, Japan. Im Rahmen einer kleinen Rundreise über Taiwan (Taipeh), Japan (Tokyo, Kyoto, Osaka) und Singapur, werden wir wieder viele positive Begegnungen haben, und vielfältige Eindrücke mitnehmen. Siehe dazu auch unsere Reisen.
In dem Blogbeitrag Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data hatte ich schon erläutert, wie wichtig es ist, dass sich Organisationen und auch Privatpersonen nicht nur an den bekannten AI-Modellen der Tech-Giganten orientieren. Ein wichtiges Kriterien sind die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen.
In Europa haben wir gegenüber China und den USA in der Zwischenzeit ein eigenes Verständnis von der gesellschaftlichen Nutzung der Künstlichen Intelligenz entwickelt (Blogbeitrag). Dabei spielen die technologische Unabhängigkeit (Digitale Souveränität) und die europäische Kultur wichtige Rollen.
Die jeweiligen europäischen Kulturen drücken sich in den verschiedenen Sprachen aus, die dann auch möglichst Bestandteil der in den KI-Modellen genutzten Trainingsdatenbanken (LLM) sein sollten – damit meine ich nicht die Übersetzung von englischsprachigen Texten in die jeweilige Landessprache.
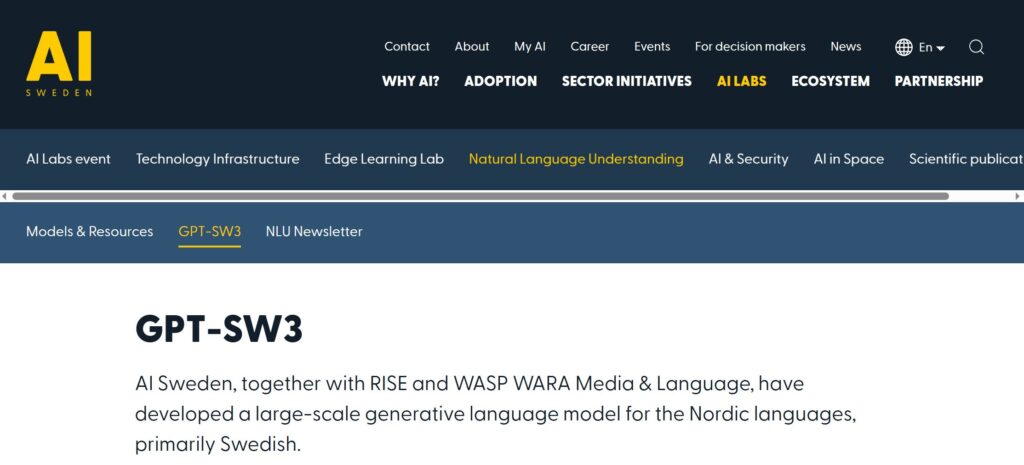
Ein Beispiel für so eine Entwicklung ist AI SWEDEN mit dem veröffentlichten GPT-SW3 (siehe Abbildung). Das LLM ist im Sinne der Open Source Philosophie (FOSS: Free Open Source Software) transparent und von jedem nutzbar – ohne Einschränkungen.
“GPT-SW3 is the first truly large-scale generative language model for the Swedish language. Based on the same technical principles as the much-discussed GPT-4, GPT-SW3 will help Swedish organizations build language applications never before possible” (Source).
Für schwedisch sprechende Organisationen – oder auch Privatpersonen – bieten sich hier Möglichkeiten, aus den hinterlegten schwedischen Trainingsdaten den kulturellen Kontext entsprechend Anwendungen zu entwickeln. Verfügbar ist das Modell bei Huggingface.
In den Diskussionen um Künstliche Intelligenz (Artificial Intelligence) werden die Tech-Riesen nicht müde zu behaupten, dass Künstliche Intelligenz die Menschliche Intelligenz ebenbürtig ist, und es somit eine Generelle Künstliche Intelligenz (AGI: Artificial General Intelligence) geben wird.
Dabei wird allerdings nie wirklich geklärt, was unter der Menschlichen Intelligenz verstanden wird. Wenn es der Intelligenz-Quotient (IQ) ist, dann haben schon verschiedene Tests gezeigt, dass KI-Modelle einen IQ erreichen können, der höher ist als bei dem Durchschnitt der Menschen. Siehe dazu OpenAI Model “o1” hat einen IQ von 120 – ein Kategorienfehler?Heißt das, dass das KI-Modell dann intelligenter ist als ein Mensch? Viele Experten bezweifeln das:
“Most experts agree that artificial general intelligence (AGI), which would allow for the creation of machines that can basically mimic or supersede human intelligence on a wide range of varying tasks, is currently out of reach and that it may still take hundreds of years or more to develop AGI, if it can ever be developed. Therefore, in this chapter, “digitalization” means computerization and adoption of (narrow) artificial intelligence” (Samaan 2024, in Werthner et al (eds.) 2024, in Anlehnung an https://rodneybrooks.com/agi-has-been-delayed/).
Es wird meines Erachtens Zeit, dass wir Menschliche Intelligenz nicht nur auf den IQ-Wert begrenzen, sondern entgrenzen. Die Theorie der Multiplen Intelligenzen hat hier gegenüber dem IQ eine bessere Passung zu den aktuellen Entwicklungen. Den Vergleich der Künstlichen Intelligenz mit der Menschlichen Intelligenz nach Howard Gardner wäre damit ein Kategorienfehler.
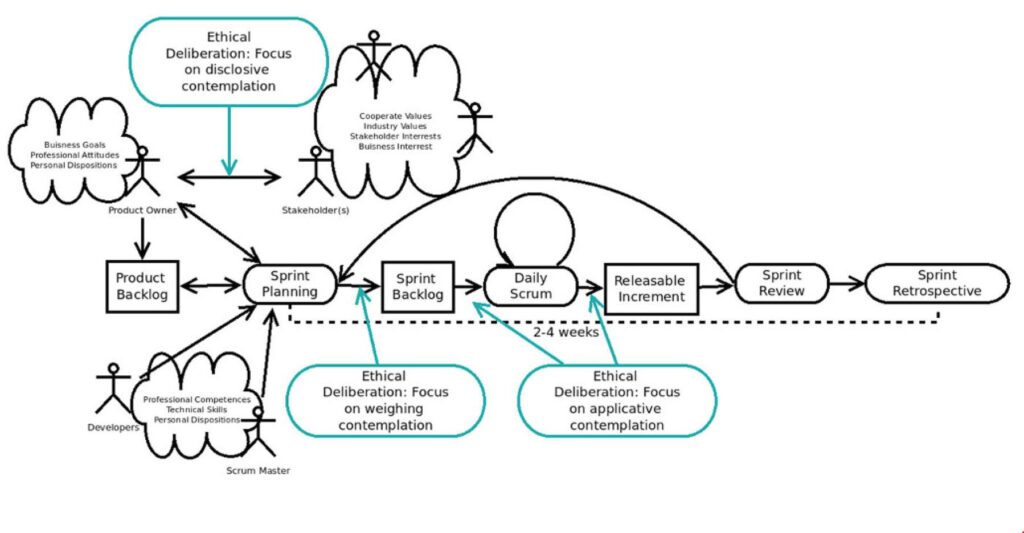
Embedding ethical deliberations into Scrum; based on Zuber et al. (2022) http:// creativecommons.org/licenses/by/4.0/, zitiert in Zuber et al (2024) in Werther et al. (eds) (2024)
Wenn es um Technik geht wird immer wieder die Frage nach der Ethik gestellt, denn Technik kann zum Wohle oder zum Nachteil von (allen) Menschen und der Umwelt genutzt werden. Aktuell geht es dabei beispielsweise um die Ethik bei der Nutzung von Künstlicher Intelligenz. Siehe dazu auch Technikethik (Wikipedia).
In der Softwareentwicklung hat sich der Einsatz von Scrum als Rahmenwerk (Framework) bewährt. In der Abbildung sind die verschiedenen Events, Artefakte und Rollen zu erkennen. Die Autoren Zuber et al. (2024) schlagen nun vor, ethische Überlegungen (ethical deliberations) mit in das Scrum-Framework einzubauen. Diese sind in der Abbildung grün hervorgehoben.
“The core idea is that, before the regular agile cadence begins, in a sprint 0, we first proceed descriptively and align ourselves with societal and organizational value specifications, i.e., we start from a framework defined by society and organization. Second, in the relationship between the product owner and the client, central ethical values are identified within this framework on a project-specific basis, if necessary, and become part of the product backlog. This can be done on the basis of existing codes of conduct or with other tools and methods that are specific to culture and context. We call this the normative horizon that is established during disclosive contemplation. Value-Sensitive Software Design: Ethical Deliberation in Agile. Within each individual sprint, it is a matter of identifying new values and implementing normative demands through suitable technical or organizational mechanisms” (Zuber et al 2024, in Werther et al (eds.) 2024).
Es ist wichtig, dass wir uns mit den ethischen Fragen neuer Technologien wie z.B. der Künstliche Intelligenz auseinandersetzen und es nicht zulassen, dass Tech-Konzerne die Vorteile der neuen Möglichkeiten in Milliarden von Dollar Gewinn ummünzen, und die sozialen Folgen der der neuen KI-Technologien auf die Gesellschaft abwälzen. Hier muss es eine Balance geben, die durch ethische Fragestellungen in den Entwicklungsprozessen von Technologien mit integriert sein sollten – nicht nur im Scrum-Framework.
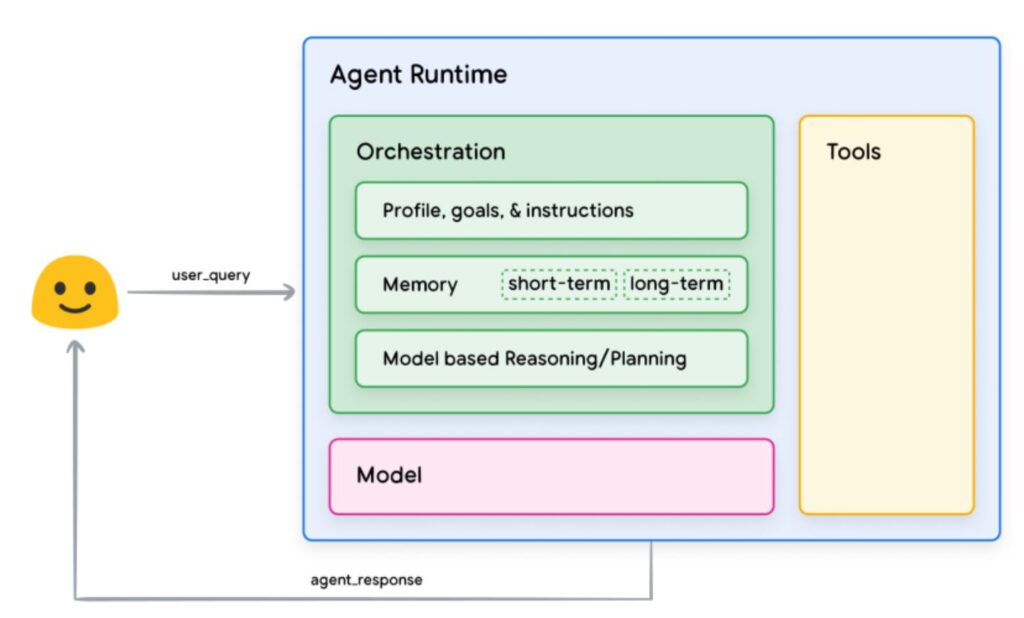
General agent architecture and components (Wiesinger et al. (2024): Agents)
In der letzten Zeit kommt immer mehr der Begriff AI Agent – oder auch Gen AI Agent – auf. Mit Hilfe der Abbildung möchte ich die Zusammenhänge der verschiedenen Komponenten erläutern.
Die Modelle (Model), oft als Language Models, Small Language Models oder Large Language Models (LLM) bezeichnet, enthalten eine sehr große Menge an Trainingsdaten. Dabei können Open Source AI Models, Open Weights Models und Closed AI Models unterschieden werden. An dieser Stelle merkt man schon, wie wichtig die Auswahl eines geeigneten Modells ist. Diese Modelle sind üblicherweise nicht auf typische Tools oder Kombinationen von Tools trainiert. Oftmals wird dieser Teil dann mit Hilfe von immer detaillierteren Eingaben (Prompts, Dateien etc.) des Users spezifiziert.
Die Beschränkungen von Modellen bei der Interaktion mit der “äußeren Welt” kann durch geeignete Tools erweitert werden. Dazu können spezielle Datenbanken, API-Schnittstellen usw. genutzt werden. Siehe dazu auch RAG: KI-Basismodelle mit eigener Wissensbasis verknüpfen.
Der AI Agent orchestriert nun alle Komponenten, wie die Eingabe des Users, das jeweilige Modell (oder sogar mehrere), die Tools und gibt das Ergebnis (Output) für den User in der gewünschten Form aus.
Die Möglichkeit, AI Agenten zu erstellen, bieten in der Zwischenzeit viele kommerzielle KI-Anbieter an. Wir gehen demgegenüber den Weg, Open Source AI auf unserem Server zu installieren und zu nutzen:
AI Agenten konfigurieren wir mit Langflow (Open Source). Dabei können wir in Langflow auf sehr viele Open Source AI Modelle über Ollama (Open Source) zugreifen, und vielfältige Tools integrieren. Alle Daten bleiben dabei auf unserem Server.
Die aktuellen Entwicklungen zeigen unsere (europäische) digitale Abhängigkeit von amerikanischen Tech-Riesen. Ob es sich um Starlink, ein Unternehmen von Elon Musk, oder um OpenAI (dominiert von Microsoft), Amazon Cloud, Google usw. handelt, überall haben sich die amerikanischen Tech-Unternehmen in Europa durchgesetzt.
Immer mehr Privatpersonen, Unternehmen und Verwaltungen überlegen allerdings aktuell, ob es nicht besser ist, europäische Alternativen zu nutzen, um die genannte digitale Abhängigkeit zu reduzieren.
Die Website European alternatives for digital products hat nun angefangen, verschiedene europäische Alternativen zu den etablierten Angeboten aufzuzeigen. Die Übersicht ist nach verschiedenen Kategorien gegliedert. Die Website ist eine Initiative eines österreichischen Softwareentwicklers und steht erst am Anfang.
Insgesamt kann diese Website in die Initiative Sovereign Workplace eingeordnet werden, an dem wir uns auch schon länger orientieren. Dabei werden Vorschläge gemacht, welche Anwendungen auf Open Source Basis geeignet erscheinen.
Gerade Kleine und Mittlere Unternehmen (KMU) können es sich oftmals nicht leisten, eigene Trainingsmodelle (Large Language Models) zu entwickeln. KMU greifen daher gerne auf bekannte Modelle wie ChatGPT usw. zurück.
Es wird allerdings gerade bei innovativen KMU immer klarer, dass es gefährlich sein kann, eigene Datenbestände in z.B. ChatGPT einzugeben. Da diese Modelle nicht transparent sind ist unklar, was mit den eigenen Daten passiert.
Eine Möglichkeit aus dem Dilemma herauszukommen ist, RAG (Retrieval-Augmented Generation) zu nutzen – also ein Basismodell mit einer internen Wissensbasis zu verknüpfen:
“Retrieval-Augmented Generation (RAG): Bei RAG wird ein Basismodell wie GPT-4, Jamba oder LaMDA mit einer internen Wissensbasis verknüpft. Dabei kann es sich um strukturierte Informationen aus einer Datenbank, aber auch um unstrukturierte Daten wie E-Mails, technische Dokumente, Whitepaper oder Marketingunterlagen handeln. Das Foundation Model kombiniert die Informationen mit seiner eigenen Datenbasis und kann so Antworten liefern, die besser auf die Anforderungen des Unternehmens zugeschnitten sind” (heise business services (2024): KI für KMU: Große Sprachmodelle erfolgreich einsetzen – mit Finetuning, RAG & Co.).
Wir gehen noch einen Schritt weiter, indem wir (1) einerseits LocalAI und Open Source AI mit einem Assistenten nutzen, und (2) darüber hinaus mit Hilfe von Ollama und Langflow eigene KI-Agenten entwickeln, die auf Basis von Open Source AI Modellen und beliebig konfigurierbaren eigenen Input einen gewünschten Output generieren In dem gesamten Prozess bleiben alle Daten auf unserem Server.
Was passiert eigentlich mit meinen Daten, wenn ich Künstliche Intelligenz nutze? Bei Anweisungen (Prompts) an das jeweilige KI-Modell ist oft nicht klar, was mit den Daten passiert, da viele der bekannten Modelle – wie beispielsweise ChatGPT – Closed Source Models, also nicht transparent sind.
Gerade wenn es um persönliche Daten geht, ist das unangenehm. Es ist daher sehr erfreulich, dass die Entwicklung eines Tools, dass die privaten Daten schützt öffentlich gefördert wurde und als Open Source Anwendung frei zur Verfügung steht.
“Mit der kostenlosen Anwendung Private Prompts bleiben deine Daten dort, wo sie hingehören – bei dir auf deinem Rechner. Die Entwicklung von Private Prompts wird im Zeitraum 1.9.2024-28.02.2025 gefördert durch das Bundesministerium für Bildung und Forschung und den Prototype Fund (Förderkennzeichen 01IS24S44)” (Quelle: https://www.privateprompts.org/).
Wir gehen noch einen Schritt weiter, in dem wir LocalAI auf unserem Server installiert haben. Wir nutzen dabei verschiedene Modelle, die als Open Source AI bezeichnet werden können. Siehe dazu
Mit Hilfe der hybriden WettbewerbsstrategieMass Customization (PDF) ist es Unternehmen möglich, Produkte zu individualisieren, ohne dass der Preis höher ist, als bei massenhaft hergestellten Produkten. Kernelement ist dabei ein Konfigurator, mit dem der Kunde selbst in einem definierten Lösungsraum (fixed solution space) vielfältige Möglichkeiten zusammenstellen kann. In der Zwischenzeit gibt es allerdings mit Künstlicher Intelligenz noch ganz andere Optionen für Mass Customization.
Künstliche Intelligenz kann für einen Verbraucher Produkte und Dienstleistungen entwickeln und anbieten, nur auf Basis der vom Konsumenten generierten Daten – sogar ohne die aktive Mitwirkung des Konsumenten. Damit bringt Künstliche Intelligenz Mass Customization auf ein neues Level: Smart Customization.
“But this is one area where AI can take mass customization to a new level: The growth of AI and machine learning can allow us to use all the data traces consumers leave online to design a perfect product for an individual consumer, without their active involvement. AI can evolve into the ability to perfectly customize a product for a consumer, without the need for a conscious process of elicitation from the consumer. As a consumer, I could specify what I want for aesthetics, while for functional parameters, it could be the system that senses what I want and desire. An algorithm reading your Instagram profile might know better than you do about your dream shirt or dress. I see a lot of opportunity to use the data that’s out there for what I call smart customization” (Piller, Frank T. and Euchner, James, Mass Customization in the Age of AI (June 07, 2024). Research-Technology Management, volume 67, issue 4, 2024 [10.1080/08956308.2024.2350919], Available at SSRN: https://ssrn.com/abstract=4887846).
Dieser Ansatz ist natürlich für Unternehmen interessant, da sie die umständlichen und teuren Befragungen von Verbraucher nicht mehr – oder etwas weniger – benötigen, um angemessene Produkte anzubieten.
Es gibt allerdings auch noch eine andere Perspektive: Was ist, wenn die Verbraucher ihre eigenen Daten mit Hilfe von Künstlicher Intelligenz selbst nutzen, um eigene Produkte zu entwickeln? Im Extremfall – und mit Hilfe von modernen Technologien wie z.B. den 3D-Druck (Additive Manufacturing) – können sich die Verbraucher innovative Produkte selbst herstellen. Diese Option klingt etwas futuristisch, da wir es gewohnt sind, Innovationen mit Unternehmen in Verbindung zu bringen. Doch hat Eric von Hippel gezeigt, dass es immer mehr von diesen Open User Innovation gibt, die gar nicht in den üblichen Statistiken zu Innovation auftauchen. Siehe dazu auch
Wie schon in mehreren Blogbeiträgen erläutert, haben wir das Ziel, einen souveränen Arbeitsplatz zu gestalten, bei dem u.a. auch Künstliche Intelligenz so genutzt werden kann, dass alle eingegebenen und generierten Daten auf unserem Server bleiben.
Dazu haben wir LocalAI (Open Source) auf unserem Server installiert. Damit können wir aktuell aus mehr als 700 frei verfügbaren KI-Modellen je nach Bedarf auswählen. Zu beachten ist hier, dass wir nur Open Source AI nutzen wollen. Siehe dazu auch AI: Was ist der Unterschied zwischen Open Source und Open Weights Models?
Bei den verschiedenen Recherchen sind wir auch auf OLMo gestoßen. OLMo 2 ist eine LLM-Familie (Large Language Models), die von Ai2 – einer Not for Profit Organisation – entwickelt wurde und zur Verfügung gestellt wird:
“OLMo 2 is a family of fully-open language models, developed start-to-finish with open and accessible training data, open-source training code, reproducible training recipes, transparent evaluations, intermediate checkpoints, and more” (Source: https://allenai.org/olmo).
Unter den verschiedenen Modellen haben wir uns die sehr spezielle Version allenai_olmocr-7b-0225 in unserer LocalAI installiert – siehe Abbildung.
“olmOCR is a document recognition pipeline for efficiently converting documents into plain text” (ebd.)