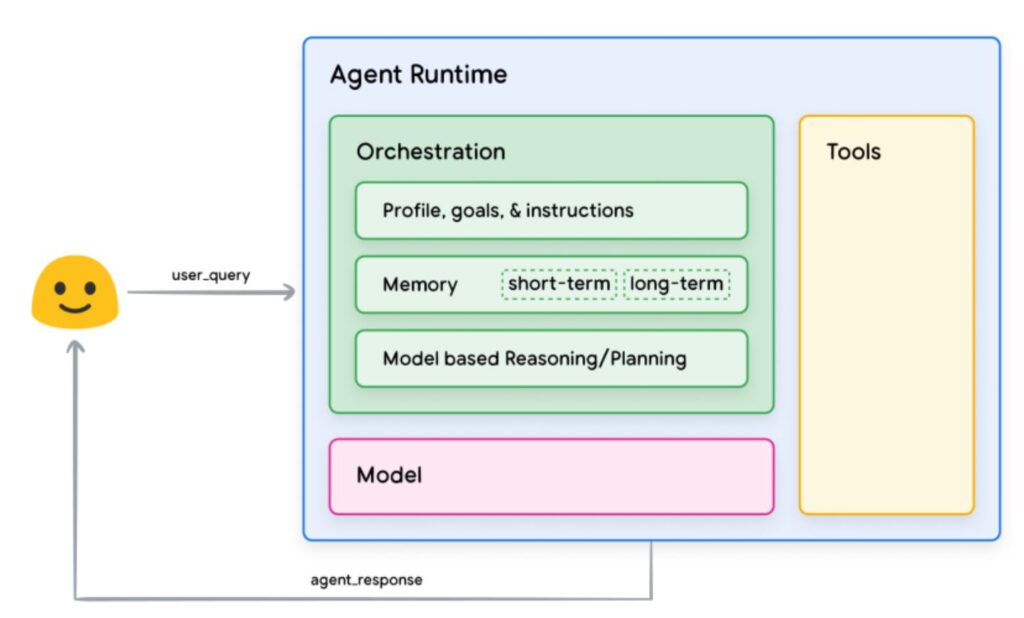
In der letzten Zeit kommt immer mehr der Begriff AI Agent – oder auch Gen AI Agent – auf. Mit Hilfe der Abbildung möchte ich die Zusammenhänge der verschiedenen Komponenten erläutern.
Die Modelle (Model), oft als Language Models, Small Language Models oder Large Language Models (LLM) bezeichnet, enthalten eine sehr große Menge an Trainingsdaten. Dabei können Open Source AI Models, Open Weights Models und Closed AI Models unterschieden werden. An dieser Stelle merkt man schon, wie wichtig die Auswahl eines geeigneten Modells ist. Diese Modelle sind üblicherweise nicht auf typische Tools oder Kombinationen von Tools trainiert. Oftmals wird dieser Teil dann mit Hilfe von immer detaillierteren Eingaben (Prompts, Dateien etc.) des Users spezifiziert.
Die Beschränkungen von Modellen bei der Interaktion mit der “äußeren Welt” kann durch geeignete Tools erweitert werden. Dazu können spezielle Datenbanken, API-Schnittstellen usw. genutzt werden. Siehe dazu auch RAG: KI-Basismodelle mit eigener Wissensbasis verknüpfen.
Der AI Agent orchestriert nun alle Komponenten, wie die Eingabe des Users, das jeweilige Modell (oder sogar mehrere), die Tools und gibt das Ergebnis (Output) für den User in der gewünschten Form aus.
Die Möglichkeit, AI Agenten zu erstellen, bieten in der Zwischenzeit viele kommerzielle KI-Anbieter an. Wir gehen demgegenüber den Weg, Open Source AI auf unserem Server zu installieren und zu nutzen:
AI Agenten konfigurieren wir mit Langflow (Open Source). Dabei können wir in Langflow auf sehr viele Open Source AI Modelle über Ollama (Open Source) zugreifen, und vielfältige Tools integrieren. Alle Daten bleiben dabei auf unserem Server.