In verschiedenen Blogbeiträgen hatte ich darauf hingewiesen, dass es für Organisationen in Zukunft immer wichtiger wird, die digitale Abhängigkeiten von kommerziellen IT-/AI-Anbietern zu reduzieren – auch bei der Anwendung von Künstlicher Intelligenz (AI: Artificial Intelligence), da die Trainingsdatenbanken der verschiedenen Anbieter
(1) nicht transparent sind,
(2) es zu Urheberrechtsverletzungen kommen kann,
(3) und nicht klar ist, was mit den eigenen eingegeben Daten, z.B. über Prompts oder hochgeladenen Dateien, passiert.
Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich. Nicht zuletzt werden die Kosten für die KI-Nutzung immer höher – beispielsweise bei Microsoft und der Nutzung des KI-Assistenten Copilot: KI treibt Microsoft-365-Preise in die Höhe (golem vom 17.01.2025).
Es ist natürlich leicht, darüber zu schreiben und die Dinge anzuprangern, schwieriger ist es, Lösungen aufzuzeigen, die die oben genannten Punkte (1-3) umgehen. Zunächst einmal ist die Basis von einer Lösung Free Open Source Software (FOSS). Eine FOSS-Alternative zu OpenAI, Claude usw. haben wir auf einem Server installiert und die ersten drei Modelle installiert. Was bedeutet das?
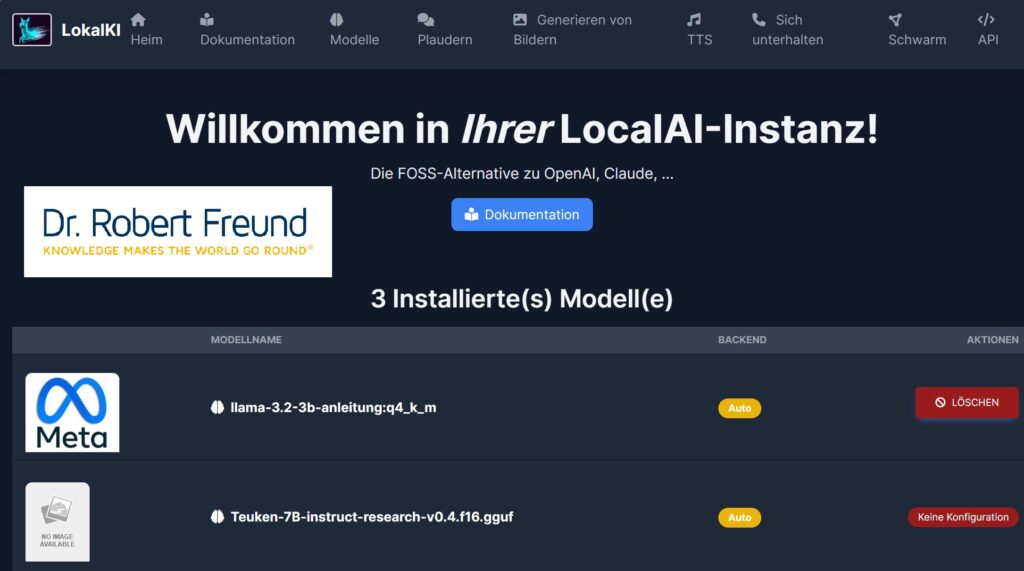
Wenn wir in einem Chat einen Prompt (Text, Datei..) eingeben, greift das System auf das ausgewählte Modell (LLM: Large Language Model) zu, wobei die Daten (Eingabe, Verarbeitung, Ausgabe) alle auf unserem Server bleiben.
Wie in der Abbildung zu sehen ist, haben wir neben Llama 3.2 auch Teuken 7B hinterlegt. Gerade Teuken 7B basiert auf einem europäischen Ansatz für eine Trainingsdatenbank (LLM) in 24 Sprachen der Europäischen Union. Siehe dazu Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data.
Wir werden diese Modelle in der nächsten Zeit testen und unsere Erkenntnisse in Blogbeiträgen darstellen.