Wir (Jutta und ich) sind Fans der EXPO, da die Weltausstellungen die vielen positiven Seiten der Welt zeigen. Die Länder-Pavilions zeigen neue, innovative und interessante Entwicklungen, aus allen Regionen der Welt.
Wir haben schon verschiedene Weltausstellungen besucht, u.a. natürlich die Weltausstellungen in Hannover, in Mailand und Dubai. In Dubai waren wir sogar über Silvester, was noch einmal einen besonderen Kick ergab.
Jetzt also die Expo 2025 in Osaka, Japan. Im Rahmen einer kleinen Rundreise über Taiwan (Taipeh), Japan (Tokyo, Kyoto, Osaka) und Singapur, werden wir wieder viele positive Begegnungen haben, und vielfältige Eindrücke mitnehmen. Siehe dazu auch unsere Reisen.
In dem Blogbeitrag Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data hatte ich schon erläutert, wie wichtig es ist, dass sich Organisationen und auch Privatpersonen nicht nur an den bekannten AI-Modellen der Tech-Giganten orientieren. Ein wichtiges Kriterien sind die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen.
In Europa haben wir gegenüber China und den USA in der Zwischenzeit ein eigenes Verständnis von der gesellschaftlichen Nutzung der Künstlichen Intelligenz entwickelt (Blogbeitrag). Dabei spielen die technologische Unabhängigkeit (Digitale Souveränität) und die europäische Kultur wichtige Rollen.
Die jeweiligen europäischen Kulturen drücken sich in den verschiedenen Sprachen aus, die dann auch möglichst Bestandteil der in den KI-Modellen genutzten Trainingsdatenbanken (LLM) sein sollten – damit meine ich nicht die Übersetzung von englischsprachigen Texten in die jeweilige Landessprache.
Ein Beispiel für so eine Entwicklung ist AI SWEDEN mit dem veröffentlichten GPT-SW3 (siehe Abbildung). Das LLM ist im Sinne der Open Source Philosophie (FOSS: Free Open Source Software) transparent und von jedem nutzbar – ohne Einschränkungen.
“GPT-SW3 is the first truly large-scale generative language model for the Swedish language. Based on the same technical principles as the much-discussed GPT-4, GPT-SW3 will help Swedish organizations build language applications never before possible” (Source).
Für schwedisch sprechende Organisationen – oder auch Privatpersonen – bieten sich hier Möglichkeiten, aus den hinterlegten schwedischen Trainingsdaten den kulturellen Kontext entsprechend Anwendungen zu entwickeln. Verfügbar ist das Modell bei Huggingface.
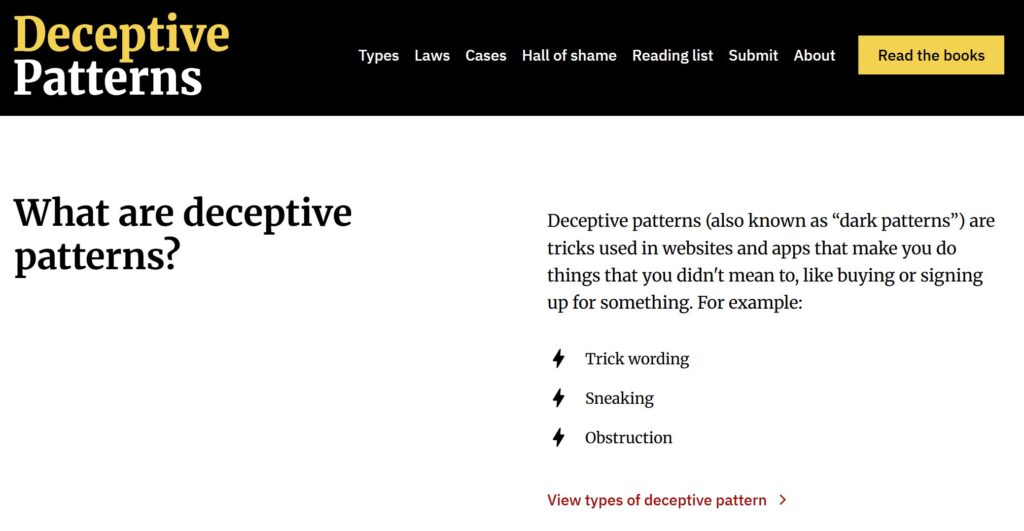
ChatGPT forces users to compromise on privacy by linking it to reduced functionality Dark patterns are another issue. By default, ChatGPT users allow OpenAI to use their data for model training, exposing them to memorization risks. The opt-out interfaces unnecessarily link privacy with reduced functionality, and the more flexible control is hard to find and use. ChatGPT | tianshi_li | September 25, 2023 Source: https://www.deceptive.design/hall-of-shame
Dazu gibt es auch eine Hall of Shame in der hunderte von Beispielen zu finden sind, die das alles verdeutlichen.
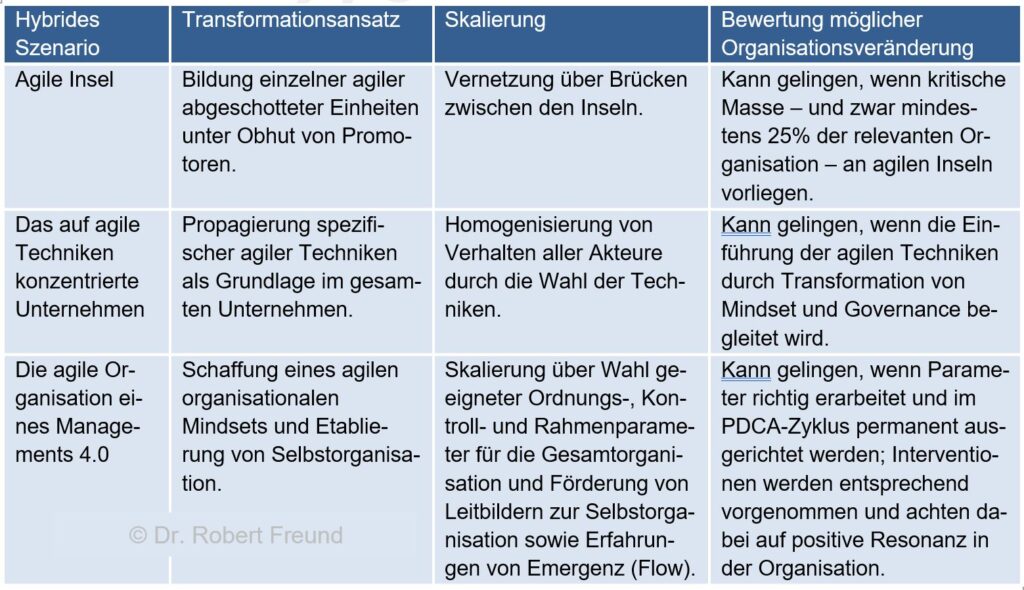
Hybride Szenarien und Transformationsansätze (Schaffitze/Fore 2020:31)
In gewachsenen Organisationen sind Arbeitsformen dominant, die auf Routinearbeit ausgerichtet sind, und ein entsprechendes Mindset ergeben. Agile Arbeitsformen sind anders, da sie in einem eher turbulenten Umfeld komplexe Problemlösungen anbieten – mit allen Konsequenzen für Organisationen.
Beide Elemente werden im Projektmanagement deutlich. Oftmals müssen beide Arbeitsformen in eine Gesamtstruktur überführt werden. Dabei stellt sich die Frage, wie agile und klassische Arbeitsformen in einer hybriden Gesamtstruktur erfolgreich sein können.
In der Tabelle sind dazu drei Hybride Szenarien mit dem jeweiligen Transformationsansatz, der Skalierungsmöglichkeit und der Bewertung möglicher Organisationsveränderungen dargestellt.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Wie die HELENA-Studie und die PMI-Studie gezeigt haben, nutzen immer mehr Unternehmen/Organisationen ein hybrides Vorgehen im Projektmanagement. Es stellt sich natürlich die Frage, wie es dazu kommen konnte. Eine Antwort dazu habe ich in einem Artikel gefunden:
“Jedes Unternehmen ist eine Art Ökosystem. In diesem Ökosystem findet ja nicht nur beispielsweise die Entwicklung von Hardware und Software statt. Da gibt es auch andere Bereiche wie Sales, Rechnungswesen oder Personalmanagement. Dort herrschen ganz klassische Geschäftsprozesse vor. Zu diesen klassischen Prozessen müssen Projekte eine Schnittstelle anbieten. Aus Sicht vieler Unternehmen liefern agile Methoden diese Schnittstellen nicht” (Kuhrmann, M. (2019): Reines agiles Vorgehen kein „Allheilmittel“, in projektmanagementaktuell 3/2019).
Daran schließt sich natürlich die Frage an, wie Unternehmen das geeignete Vorgehen für ein Projekt festlegen. Wird das hybride Vorgehensmodell nur ein Mal festgelegt, und/oder im Projektverlauf angepasst?
“Vielleicht wird die komplette Vorgehensweise nicht von Projekt zu Projekt festgelegt. Im Allgemeinen sammeln Unternehmen Erfahrungen mit ihrem Projektmanagement. Es kommt zu bestimmten Konsolidierungen im Methodenapparat, also zu Mustern, die für alle Projekte gelten. Doch innerhalb dieses konsolidierten Methodenapparats kann dann für jedes Projekt die Vorgehensweise neu zusammengestellt werden” (ebd.).
Aus der täglichen Arbeit mit und in Projekten ergeben sich also Rahmenbedingungen, die zu einer Konsolidierung bei der Methodenvielfalt führen, und damit ein Muster erkennen lassen. Dieses Muster wiederum zeigt auf, welche Vorgehensmodelle kombiniert werden sollten, um das Projekte – oder die Projekte – erfolgreich umsetzen zu können.
Es wird in Zukunft immer mehr darauf ankommen, Hybrides Projektmanagement in diesem Sinne zu professionalisieren.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
In den Diskussionen um Künstliche Intelligenz (Artificial Intelligence) werden die Tech-Riesen nicht müde zu behaupten, dass Künstliche Intelligenz die Menschliche Intelligenz ebenbürtig ist, und es somit eine Generelle Künstliche Intelligenz (AGI: Artificial General Intelligence) geben wird.
Dabei wird allerdings nie wirklich geklärt, was unter der Menschlichen Intelligenz verstanden wird. Wenn es der Intelligenz-Quotient (IQ) ist, dann haben schon verschiedene Tests gezeigt, dass KI-Modelle einen IQ erreichen können, der höher ist als bei dem Durchschnitt der Menschen. Siehe dazu OpenAI Model “o1” hat einen IQ von 120 – ein Kategorienfehler?Heißt das, dass das KI-Modell dann intelligenter ist als ein Mensch? Viele Experten bezweifeln das:
“Most experts agree that artificial general intelligence (AGI), which would allow for the creation of machines that can basically mimic or supersede human intelligence on a wide range of varying tasks, is currently out of reach and that it may still take hundreds of years or more to develop AGI, if it can ever be developed. Therefore, in this chapter, “digitalization” means computerization and adoption of (narrow) artificial intelligence” (Samaan 2024, in Werthner et al (eds.) 2024, in Anlehnung an https://rodneybrooks.com/agi-has-been-delayed/).
Es wird meines Erachtens Zeit, dass wir Menschliche Intelligenz nicht nur auf den IQ-Wert begrenzen, sondern entgrenzen. Die Theorie der Multiplen Intelligenzen hat hier gegenüber dem IQ eine bessere Passung zu den aktuellen Entwicklungen. Den Vergleich der Künstlichen Intelligenz mit der Menschlichen Intelligenz nach Howard Gardner wäre damit ein Kategorienfehler.
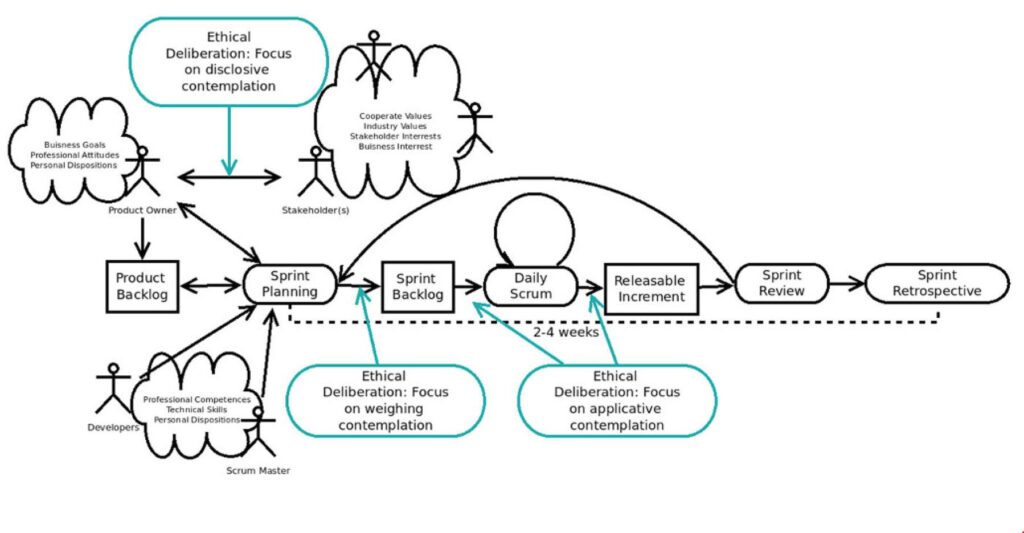
Embedding ethical deliberations into Scrum; based on Zuber et al. (2022) http:// creativecommons.org/licenses/by/4.0/, zitiert in Zuber et al (2024) in Werther et al. (eds) (2024)
Wenn es um Technik geht wird immer wieder die Frage nach der Ethik gestellt, denn Technik kann zum Wohle oder zum Nachteil von (allen) Menschen und der Umwelt genutzt werden. Aktuell geht es dabei beispielsweise um die Ethik bei der Nutzung von Künstlicher Intelligenz. Siehe dazu auch Technikethik (Wikipedia).
In der Softwareentwicklung hat sich der Einsatz von Scrum als Rahmenwerk (Framework) bewährt. In der Abbildung sind die verschiedenen Events, Artefakte und Rollen zu erkennen. Die Autoren Zuber et al. (2024) schlagen nun vor, ethische Überlegungen (ethical deliberations) mit in das Scrum-Framework einzubauen. Diese sind in der Abbildung grün hervorgehoben.
“The core idea is that, before the regular agile cadence begins, in a sprint 0, we first proceed descriptively and align ourselves with societal and organizational value specifications, i.e., we start from a framework defined by society and organization. Second, in the relationship between the product owner and the client, central ethical values are identified within this framework on a project-specific basis, if necessary, and become part of the product backlog. This can be done on the basis of existing codes of conduct or with other tools and methods that are specific to culture and context. We call this the normative horizon that is established during disclosive contemplation. Value-Sensitive Software Design: Ethical Deliberation in Agile. Within each individual sprint, it is a matter of identifying new values and implementing normative demands through suitable technical or organizational mechanisms” (Zuber et al 2024, in Werther et al (eds.) 2024).
Es ist wichtig, dass wir uns mit den ethischen Fragen neuer Technologien wie z.B. der Künstliche Intelligenz auseinandersetzen und es nicht zulassen, dass Tech-Konzerne die Vorteile der neuen Möglichkeiten in Milliarden von Dollar Gewinn ummünzen, und die sozialen Folgen der der neuen KI-Technologien auf die Gesellschaft abwälzen. Hier muss es eine Balance geben, die durch ethische Fragestellungen in den Entwicklungsprozessen von Technologien mit integriert sein sollten – nicht nur im Scrum-Framework.
Immer mehr Arbeiten sind wissensintensiv und unterscheiden sich somit von anderen Arbeitsweisen in Organisationen. Dabei gibt es oftmals einen branchenspezifischen Mix an Arbeit (BMAS 2015):
Arbeiten 1.0 bezeichnet die beginnende Industriegesellschaft und die ersten Organisationen von Arbeitern.
Arbeiten 2.0 ist die beginnende Massenproduktion und die Anfänge des Wohlfahrtsstaats am Ende des 19. Jahrhunderts.
Arbeiten 3.0 umfasst die Zeit der Konsolidierung des Sozialstaats und der Arbeitnehmerrechte auf Grundlage der sozialen Marktwirtschaft.
Arbeiten 4.0 wird vernetzter, digitaler und flexibler sein. Wie die zukünftige Arbeitswelt im Einzelnen aussehen wird, ist noch offen. Seit Beginn des 21. Jahrhundert stehen wir vor einem erneuten grundlegenden Wandel der Produktionsweise.
Die heutige Wissensarbeit unterscheidet sich in vielen Dimensionen von klassischer Routinearbeit in der Industriegesellschaft.
Die Abbildung zeigt verschiedene Typen von Arbeit, die in einem Fragebogen abgefragt werden können. In der Darstellung ist zu erkennen, dass in diesem Beispiel sequenzielles Arbeiten und standardisierte Abläufe eher niedrig bewertet werden – also kaum Bestandteil der Arbeit sind. Demgegenüber sind alle anderen Arbeitstypen sehr stark (hoch) ausgeprägt. Das deutet auf wissensintensive Arbeit hin.
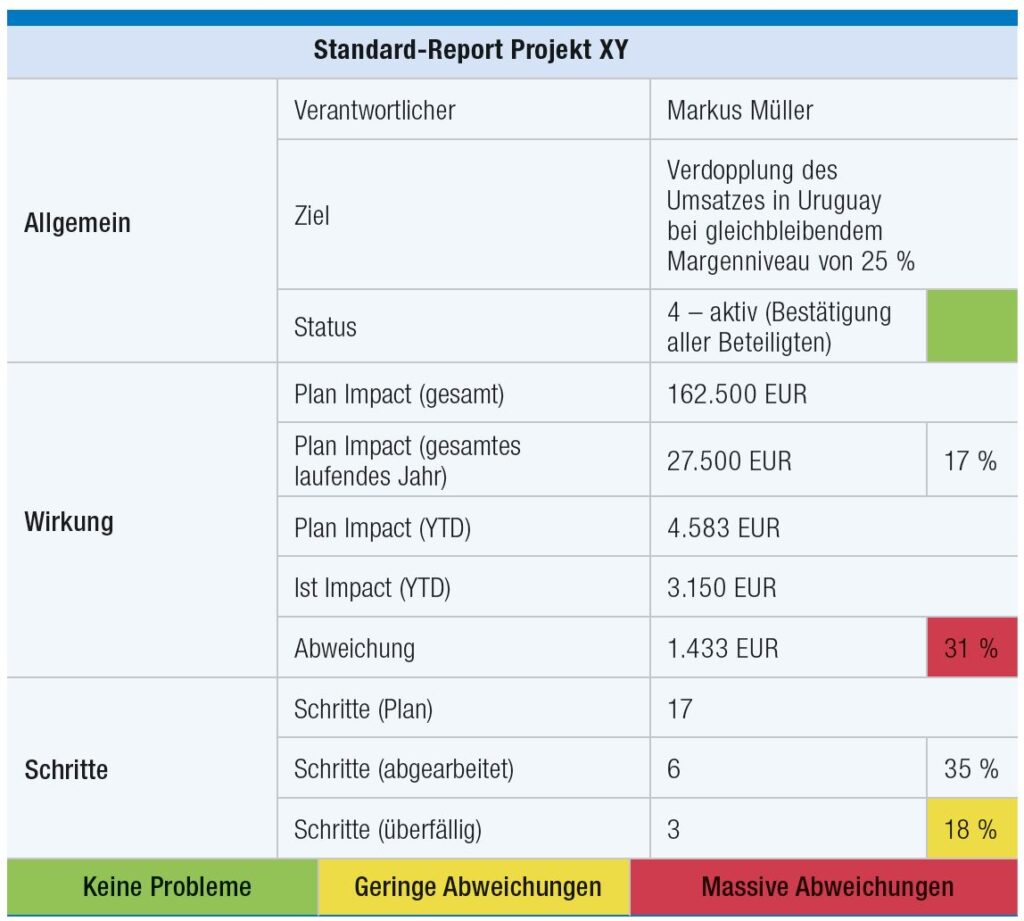
Beispiel für einen Standard-Projektreport (Jonen 2028, in projektmanagementaktuell 3/2018)
Wo stehen wir eigentlich mit unserem Projekt? Auf diese Frage kann ein Standard-Projektreport Antworten geben (Abbildung). Üblicherweise werden wichtige Parameter mit Hilfe von Ampelfarben (Rot – Gelb – Grün) hervorgehoben.
“Auf der Ebene des Einzelprojektes wird üblicherweise die Darstellung eines Standard-Projekt-Reports (Abbildung) gewählt. Dieser ermöglicht eine Verknüpfung zwischen strategischen Zielen und der Operationalisierung sowie eine ständige Darstellung des Status” (ebd.).
Zu beachten ist dabei, dass die verschiedenen Daten möglichst zu einem Stichtag erfolgen sollten da es ansonsten zu falschen Bewertungen kommen kann. Weiterhin sollte bei der Betrachtung des Status nicht nur die Vergangenheit betrachtet werden.
Mit einer Meilenstein-Trendanalyse, Kosten-Trendanalyse oder sogar einer Earned Value Prognose kann/sollte gleichzeitig auch der Blick in die Zukunft des Projekts erfolgen.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Translate »
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK